3번째 포스팅이다.
11/23 "Kubernetes Meetup" 1Day에서 발표한 이야기 연장선으로 작성한다.
고객에게 오퍼링을 위해 준비한 내용과 Kubernetes monitoring과 연계한 내용에 대해서 적어보려고 한다.
최근 발표를 다니면서 많이 받는 질문이 실제 사용할만 한가?라는 질문과 어떻게 활용해야 하는지에 대한 질문들을 많이 받는다.
오늘 최근 Spinnaker Summit 2018에서 중요하게 다뤘던 Kayenta 프로젝트를 가지고 이야기 해보려고 한다.
Kayenta는 자동 Canary 분석 오픈소스(Automated Canary Service(ACA))로 Spinnaker의 마이크로서비스중 하나로 동작한다.
Automated Canary Deployments에 사용되고 자세한 내용은 canary documentation을 확인하면 된다.
새 종류의 하나인 Canary는 1차 세계대전중에 인간이 해를 입기 전에 독성��가스를 탐지하는 용도로 사용되었다고 한다.
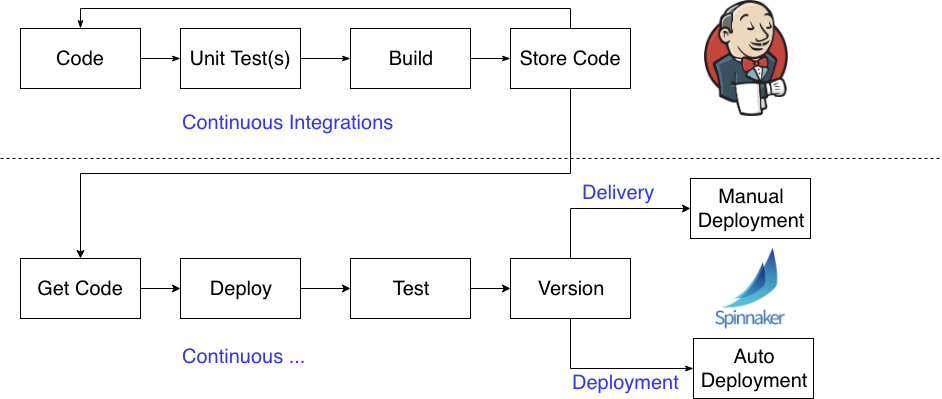
DevOps에서는 CD(Continuous Deployment) 프로세스의 일부로 사용되며 Canary 릴리즈는 새로운 버전의 Software를 Production에 배포하는 위험을 줄여주는 기술이라고 생각하면 된다.
Canary 신규 버전의 Software를 안정적인 기존 버전과 함께 배포하고 특정사용자나 일부 대상에게 트래픽 일부를 흘려 기존 사용자에게 영향을 최소하하고 새로운 버전의 문제를 신속하게 발견하고 이전의 안정된 버전으로 트래픽을 다시 라우팅시키는것이 주요 기능이라고 보면 된다.
보통 품질 테스트 용도로 현재 운영 버전과 신규 버전의 주요한 지표(주로 Prometheus Metric)를 비교하여 평가를 진행하는데 이를 단위 테스트나 통합 테스트를 대체하여 사용해서는 절대 안된다.
위에서 언급하였듯이 예기치 않은 위험을 최소화 하거나 문제를 신속하게 발견하는 것을 주 목적으로 하기 때문이다.
Spinnaker에서는 기본적으로 3가지 Cluster(Logical Application Group)를 사용한다.
- Production Cluster - 현재 실행중인 운영 버전으로 Replica는 임의로 변경할 수 있다.
- Baseline Cluster - Production Cluster와 동일한 버전으로 실행됨
- Canary Cluster - 변경된 신규 버전의 Software로 실행됨
기본적으로 수동으로 진행할 경우에는 로그와 수집된 메트릭을 분석하고 객관적인 지표로 평가를 진행하는게 기본이다.
하지만 직접 사람이 하는 일이라 메트릭 데이터를 보다 보면 편견과 착오가 발생할 수 밖에 없다.
그래서 Netflix는 ACA(Automated Canary Service)라고 하는 자동화된 접근 방식을 통해 카나리 분석을 진행하고 있다.
수동으로 계산된 여러가지 지표를 가중치 기반으로 점수를 내리고 원하는 점수��에 도달하면 배포하는 자동화된 방식이다.
- spinnaker cluster - 1.8+ (1.9.3 이상 추천)
- halyard - 1.0+
- kubernetes cluster - 1.9+
- metric services - datadog, prometheus, stackdriver, signalfx
- persistent storage - S3(or compatible S3), minio, GCS
이번 포스팅에서는 아래 환경으로 작성하였다.
- spinnaker cluster - 1.10.5
- halyard - 1.11
- kubernetes cluster - 1.9.7
- metric services - prometheus
- persistent storage - compatible S3(IBM Object Storage)
일단 기존 halyard config를 백업하자.
$ hal backup create
+ Create backup
Success
+ Successfully created a backup at location:
/Users/ddii/halbackup-Wed_Nov_28_13-35-31_KST_2018.tar
나중에 복구는 아래와 같이 하면 된다.
$ hal backup restore --backup-path <backup-name>.tar
기존 halyard config를 살펴보면 아래와 같이 canary.enabled=false 로 되어있는 것을 확인 할수 있다.
currentDeployment: default
deploymentConfigurations:
- name: default
canary
enabled: false
canary analysis을 활성화 한다.
$ hal config canary enable
그리고 default judgement algorithm은 NetflixACAJudge-v1.0 로 되어있다 다른 걸 이용하려면 다음과 같이 설정할수 있다.
$ hal config canary edit --default-judge CUSTOM_JUDGE
메트릭 소스로 prometheus를 설정한다. 물론 기존에 사용중인 prometheus endpoint url이 필요하다.
hal config canary prometheus enable
hal config canary prometheus account add my-prometheus --base-url http://YOUR_PROMETHEUS_SERVER:PORT
여기서는 IBM Cloud Object Storage(S3 Compatible)을 사용하였지만 aws로 설정한다.
$ hal config canary aws enable
$ hal config canary aws account add my-s3 --bucket spin-bucket --endpoint \
s3.seo-ap-geo.objectstorage.service.networklayer.com --access-key-id ACCESS_ID \
--secret-access-key
$ hal config canary aws edit --s3-enabled=true
여러개의 메트릭을 동시에 설정 및 수집이 가능하므로 그중 prometheus 및 관련 account를 기본으로 설정한다.
$ hal config canary edit --default-metrics-store prometheus
$ hal config canary edit --default-metrics-account my-prometheus
$ hal config canary edit --default-storage-account my-s3
모든 spinnaker cluster가 준비된 상태의 컨피그는 아래와 같다.
currentDeployment: default
deploymentConfigurations:
- name: default
canary:
enabled: true
serviceIntegrations:
- name: google
enabled: false
accounts: []
gcsEnabled: false
stackdriverEnabled: false
- name: prometheus
enabled: true
accounts:
- name: my-prometheus
endpoint:
baseUrl: http://YOUR_PROMETHEUS_SERVER:PORT
supportedTypes:
- METRICS_STORE
- name: datadog
enabled: false
accounts: []
- name: aws
enabled: true
accounts:
- name: my-s3
bucket: spin-bucket
rootFolder: kayenta
endpoint: s3.seo-ap-geo.objectstorage.service.networklayer.com
accessKeyId: ACCESS_ID
secretAccessKey: ACCESS_KEY
supportedTypes:
- OBJECT_STORE
- CONFIGURATION_STORE
s3Enabled: true
reduxLoggerEnabled: true
defaultMetricsAccount: my-prometheus
defaultStorageAccount: my-s3
defaultJudge: NetflixACAJudge-v1.0
defaultMetricsStore: prometheus
stagesEnabled: true
templatesEnabled: true
showAllConfigsEnabled: true
Spinnaker Cluster를 재배포하게 되면 아래와 같이 spin-kayenta deployments가 추가된 것을 확인할 수 있다.
$ hal deploy apply
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
spin-clouddriver-555cfc9765-kvnl8 1/1 Running 0 6d
spin-deck-85845b5b48-49ncm 1/1 Running 0 6d
spin-echo-5f9dd4d8ff-mvt7g 1/1 Running 0 6d
spin-fiat-5b945645d8-s2qcq 1/1 Running 0 6d
spin-front50-5c57fcf587-tqz28 1/1 Running 0 6d
spin-gate-57576b8c45-w5v6r 1/1 Running 0 6d
spin-kayenta-6dcd7767d6-rgb9w 1/1 Running 0 6d
spin-orca-788df6b9cc-tk6lk 1/1 Running 0 6d
spin-redis-6c87c456fc-6qbl2 1/1 Running 0 6d
spin-rosco-f6f845d49-btjnd 1/1 Running 0 6d
이후 Dashboard에 접속하고 application중 하나의 Config에 들어가면 Features에 Canary메뉴가 생긴것을 확인할 수 있다. 사용설정하고 캐싱하는데 시간이 다소 필요하고 Tasks 메뉴에서 해당 job에 대한 내용을 확인할수 있다.
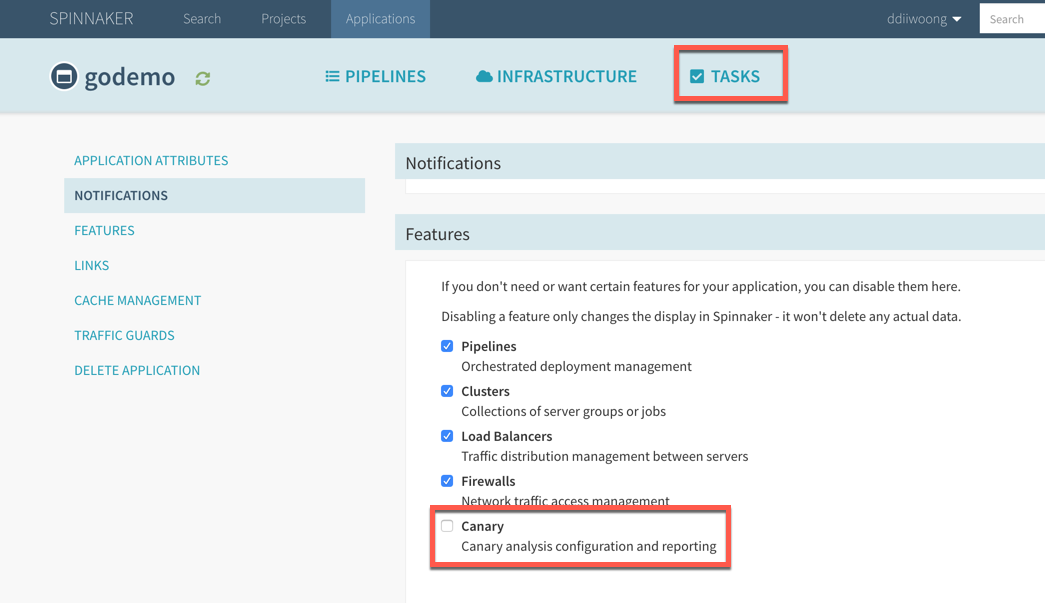
이후 application delivery 메뉴를 보면 pipelines, canary configs, canary reports라는 메뉴가 생기게 된다.

https://cloud.google.com/solutions/automated-canary-analysis-kubernetes-engine-spinnaker 가이드 처럼 구성해봐도 되나 stackdriver를 써야하고 prometheus metric을 활용한 가이드가 필요해서 적어보고자 한다.
새로 파이프라인을 추가한 다음
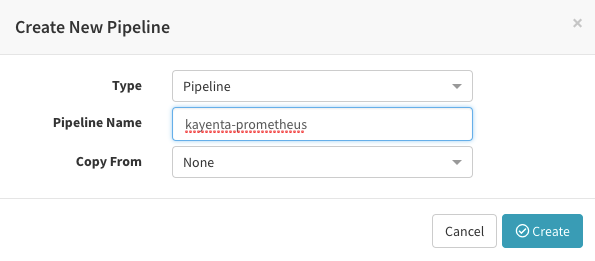
Pipeline Actions - Edit Pipeline JSON 에서
https://raw.githubusercontent.com/ddiiwoong/canary-demo-spinnaker/master/simple-deploy.json 을 추가해준다.
해당 json pipeline을 추가하고 나면 다음과 같은 화면을 확인할수 있다.
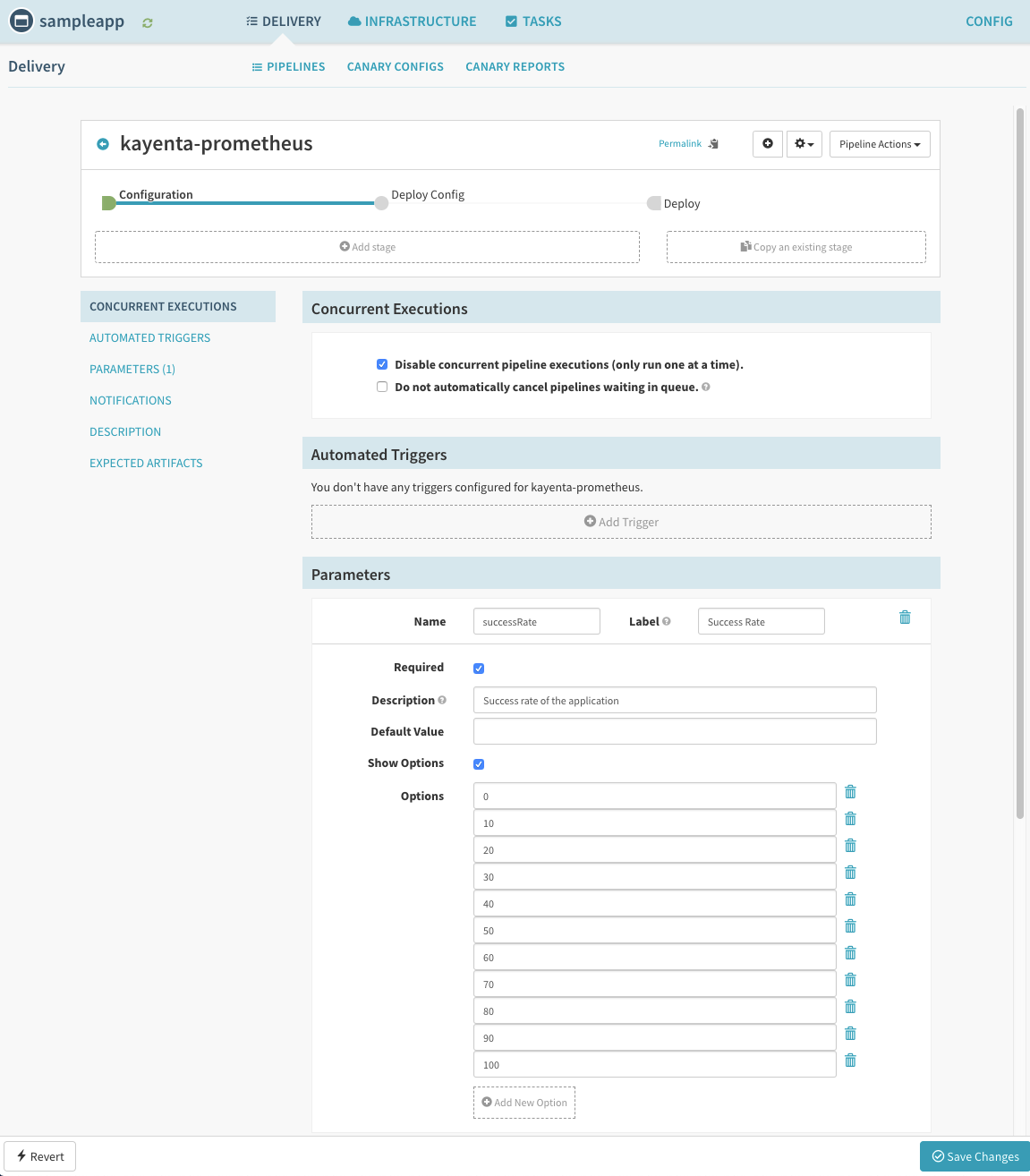
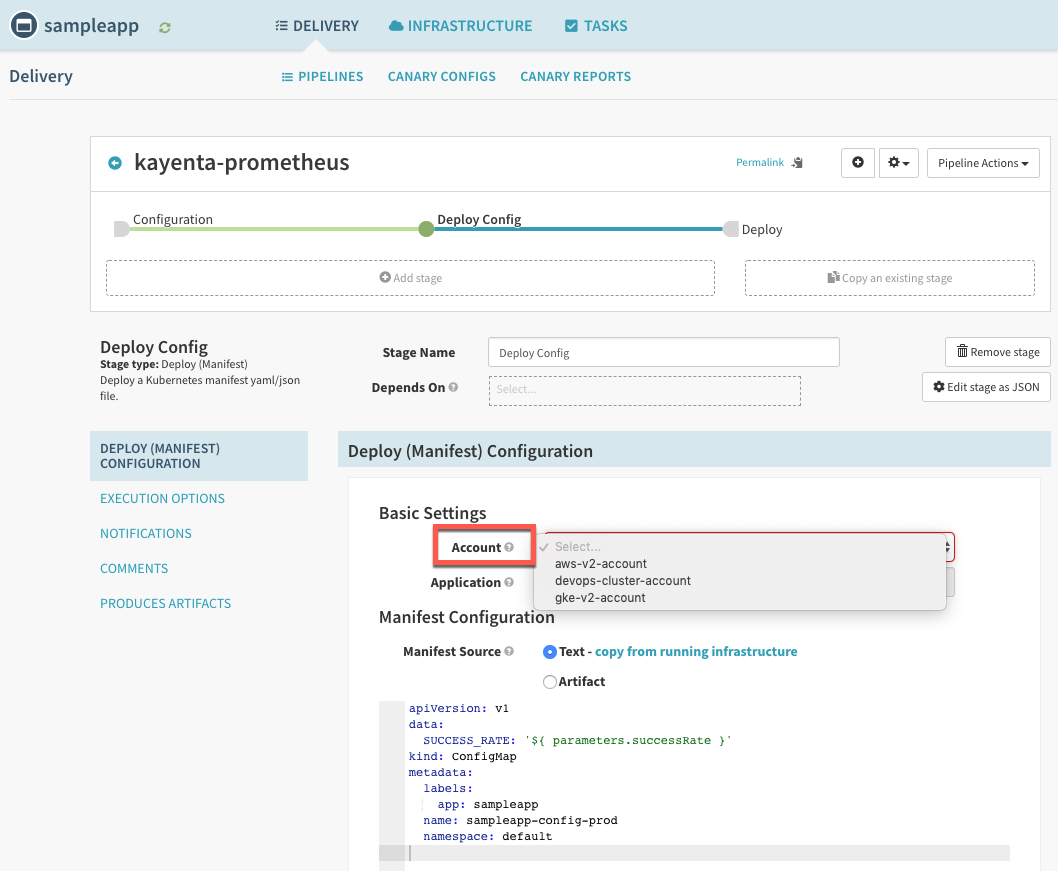
반드시 Deploy Config, Deploy Stage에서 배포할 Account 지정을 해야한다.
sampleapp image - ddiiwoong/canary-demo-spinnaker:latest
해당 pipeline내의 sampleapp은 python flask 기반으로 구성되어 간단히 internal 500 error를 원하는 비율을 configmap 변수로 구현할 수 있다. prometheus python client를 사용하여 Gauge, Counter, Metric 서버를 간단하게 구성을 해보았다. 그리고 코드내에서 500 error rate를 구한 이유는 18년 11월 기준 spinnaker kayenta 버전에서는 PromQL(rate,irate와 같은 함수) 지원이 되지 않는다. 개발중인 코드에 포함이 된것을 확인하였고 12월 kubecon때 정식 릴리즈에 포함될거라 생각한다.
#!/usr/bin/env python
from random import randrange
from flask import Flask
from prometheus_client import start_http_server, Gauge, Counter
import os
app = Flask('kayenta-tester')
c = Counter('requests', 'Number of requests served, by http code', ['http_code'])
g = Gauge('rate_requests', 'Rate of success requests')
responce_500 = 0
responce_200 = 0
rate_responce = 0
@app.route('/')
def hello():
global responce_500
global responce_200
global rate_responce
if randrange(1, 100) > int(os.environ['SUCCESS_RATE']):
c.labels(http_code='500').inc()
responce_500 = responce_500 + 1
rate_responce = responce_500 / (responce_500+responce_200) * 100
g.set(rate_responce)
return "Internal Server Error\n", 500
else:
c.labels(http_code = '200').inc()
responce_200 = responce_200 + 1
rate_responce = responce_500 / (responce_500+responce_200) * 100
g.set(rate_responce)
return "Hello World!\n"
start_http_server(8000)
app.run(host = '0.0.0.0', port = 8080)
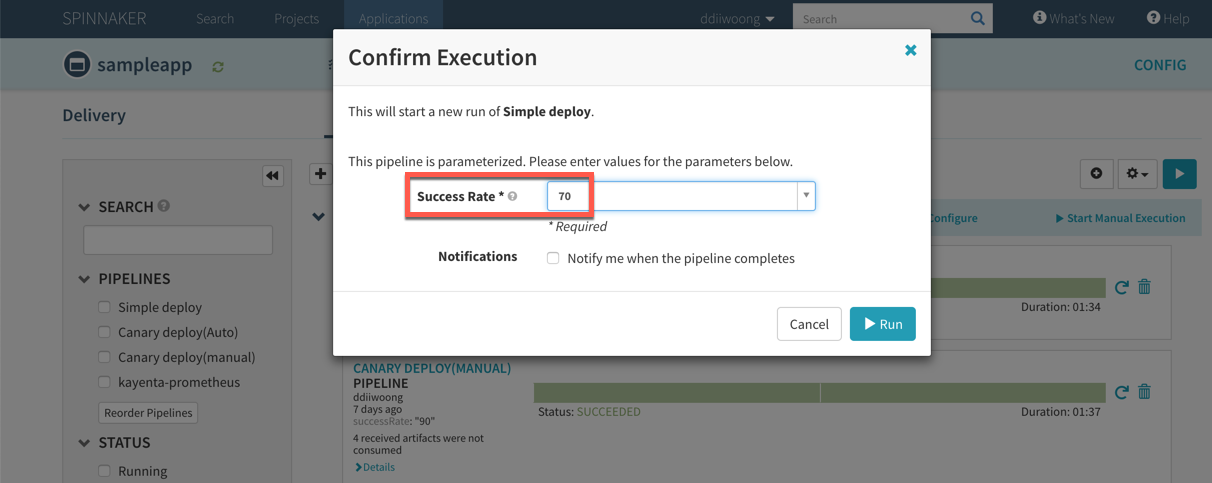
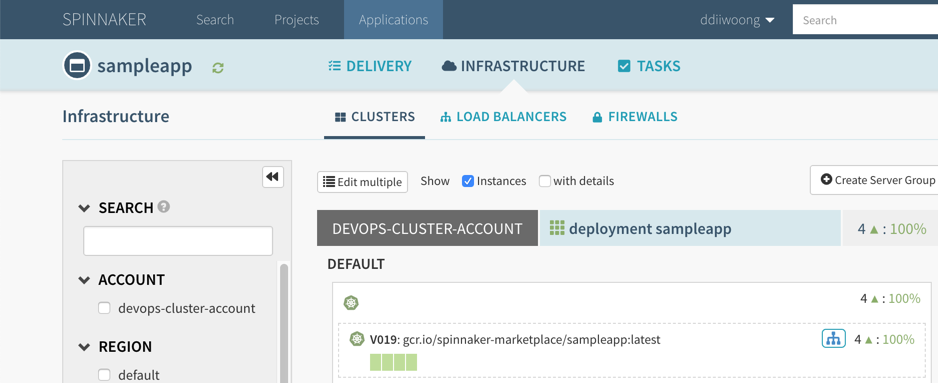
해당앱을 Start Manual Execuction을 통해 배포한다. Comfirm Execution창에서 SUCCESS_RATE를 원하는 값(예:70%)으로 선택하고 배포를 하고 나면 Infrastructure - Clusters 메뉴에서 해당 샘플앱을 확인할 수 있다.
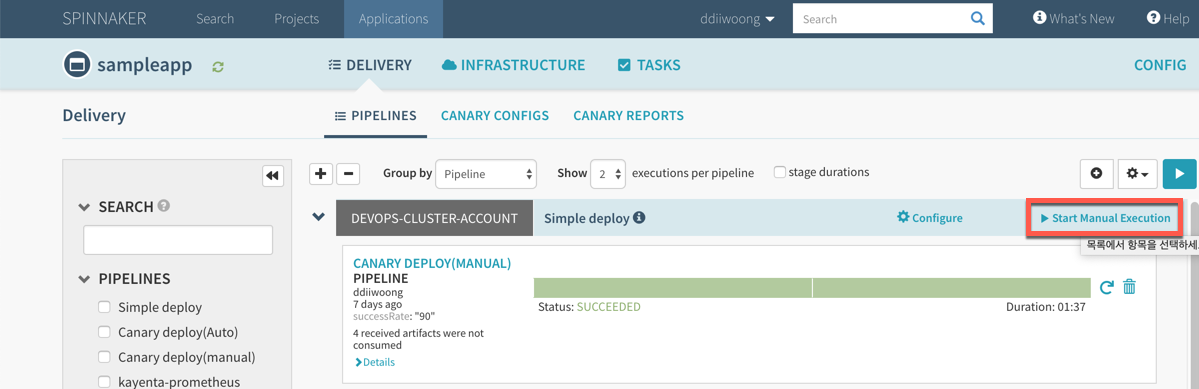
실제 해당 서비스를 접속해보면 위에 설정한 SUCCESS_RATE 비율로 200화면과 500에러를 확인할 수 있다.
해당 메트릭의 통계를 확인하기 위해 curl을 반복적으로 실행하는 injection container 를 실행한다.
kubectl -n default run injector --image=alpine -- \
/bin/sh -c "apk add --no-cache --yes curl; \
while true; do curl -sS --max-time 3 \
http://sampleapp:8080/; done"
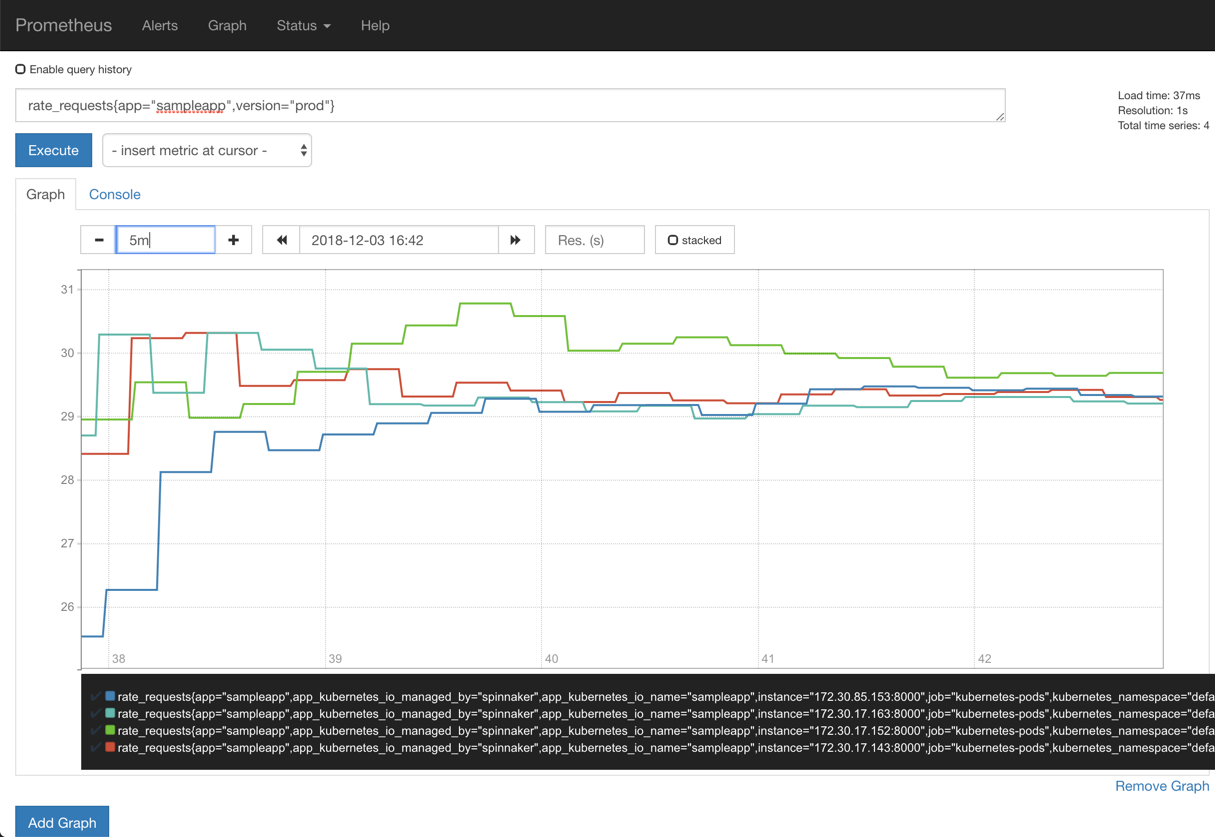
5분정도 후에 Prometheus로 접속하여 코드내 작성한 rate_requests 메트릭을 확인해본다.
PromQL은 아래 쿼리를 실행하였다.
rate_requests{app="sampleapp",version="prod"}
아래 그림과 같이 4개의 pod에서 70% 정도 200 OK, 30% 정도 500 Error가 발생하는 것을 확인할 수 있다.
이 메트릭을 Spinnaker 에서 확인하기 위해 Canary Pipeline을 만들자.
https://raw.githubusercontent.com/ddiiwoong/canary-demo-spinnaker/master/automated-canary.json를 JSON으로 Pipeline을 생성한다.
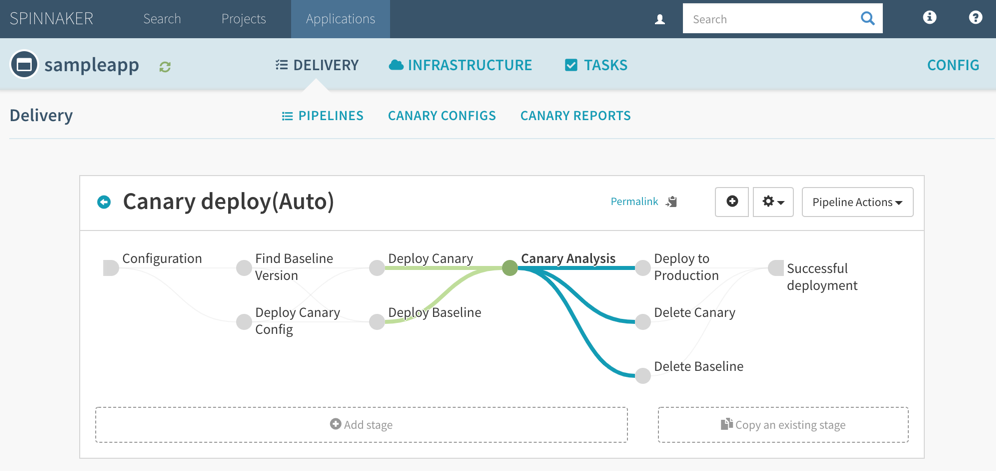
Stage별로 살펴 보기전에
- Prerequisite
Canary Config 구성이 먼저 필요하다. Delivery - Canary Configs 메뉴에서 신규 컨피그를 작성한다.
- Configuration Name -
kayenta-test
- Filter Templates 메뉴를 먼저 생성한다. Canary, Baseline구분을 위해 version 정보를 선택하였다.
- Metrics - Add Metric 은 분석을 위한 Prometheus Metric을 �설정하는 단계로
error_rate가 증가(increase)하면 Pipeline을 중단시키고 Metric은 앞에서 확인한 rate_requests를 지정한다. Filter Template은 위에서 지정한 version을 선택한다. 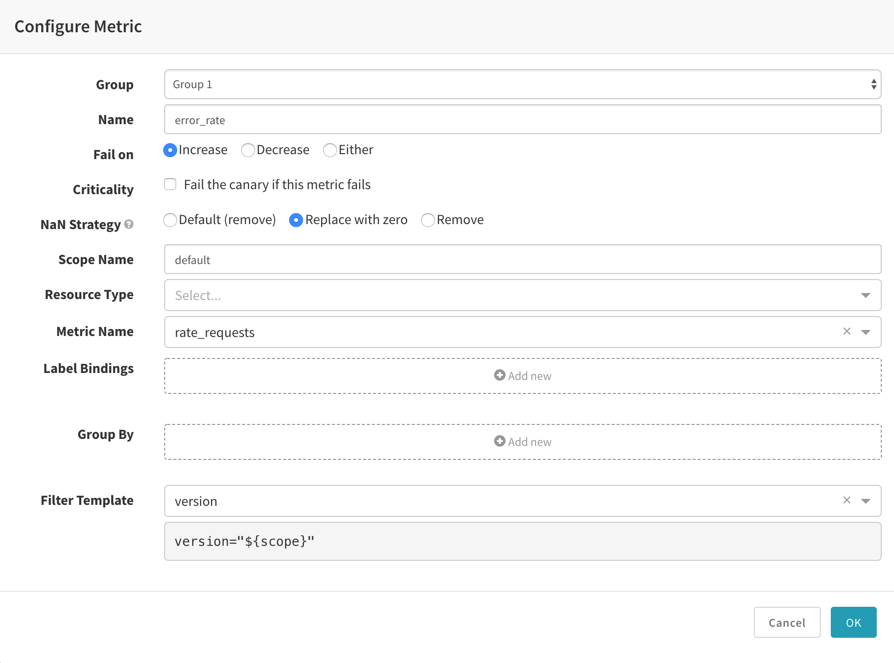
- SCORING - 어짜피 예제는 한가지 Metric분석으로 0점 아니면 100점으로 나올것이므로 Maginal 75, Pass 95를 설정한다.
- 1st Stage
- Configuration - Pipeline 실행시 초기 입력값(0-100, 10단위)으로 설정가능한 successRate 라는 Parameter를 설정한다.
- 2nd Stage
- Find Baseline - 위에서 작성한 기본 Deploy Pipeline이 선택되었는지와 확인한다.
- Deploy Canary Config - 앞에서 선택한 새로운 Parameter(successRate)를 신규 배포할 Canary Pod ConfigMap으로 설정하는 단계이다.
- 3rd Stage
- Deploy Canary - yaml manifest로 Canary 버전을 배포한다. Replicas는 1로 설정하였고 배포될 Account(K8s Cluster)를 지정한다.
- Deploy Baseline - yaml manifest로 Baseline 버전을 배포한다. 위와 동일하게 Replicas는 1로 설정하였고 배포될 Account(K8s Cluster)를 지정한다.
- 4th Stage
- Canary Analysis - 중요한 Canary 분석 단계로 아래와 같이 설정을 확인한다. Prerequisite에서 설정한 Config(
kayenta-test)를 선택하고 짧은 분석을 위해 1분(60초) 간격으로 3번 수행을 하도록 한다. Filter Template에서 지정한 version(version="${scope}") 분석을 위해 Baseline, Canary 설정을 하고 Location은 Namespaces로 생각하면 된다. 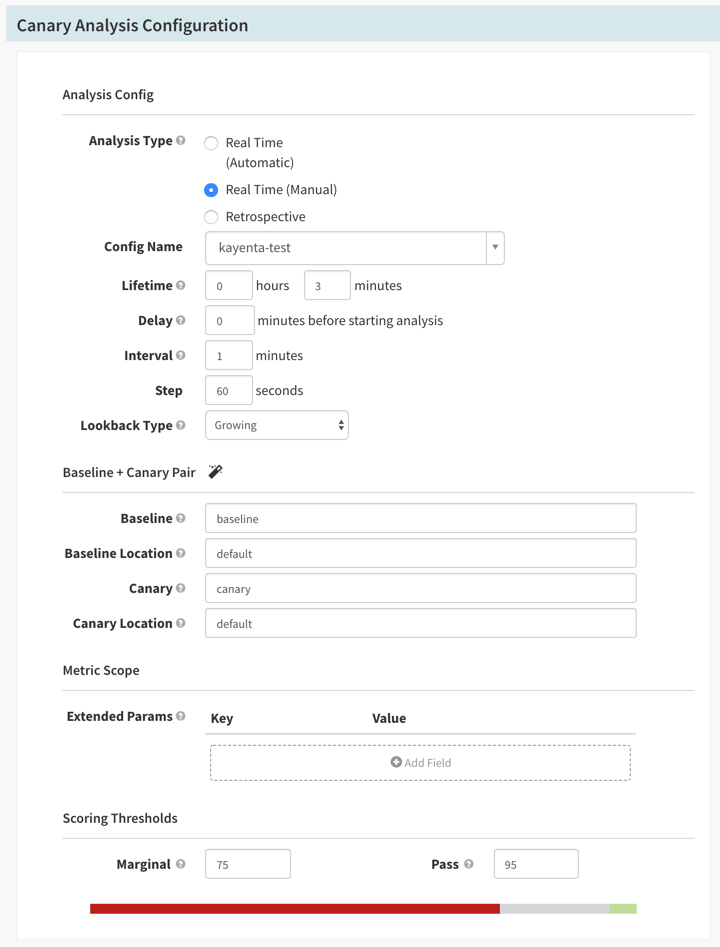
- 5th Stage
- Deploy to Production - Canary 분석이 통과하였을 경우 운영에 배포
- Delete Canary, Delete Baseline - 성공이던 실패이던 Canary, Baseline 배포본을 삭제
- 6th Stage
- Successful deployment - Canary 분석이 통과하였을 경우 최종 완료 표기하는 단계
설정이 마무리가 되면 저장을 하고 Canary 분석에 들어간다.
최초에 successRate을 70으로 배포했다면 그 이하로 설정했을 경우에는 아래와 같이 Score 0점으로 배포가 실패하고 Pipeline이 종료된다.
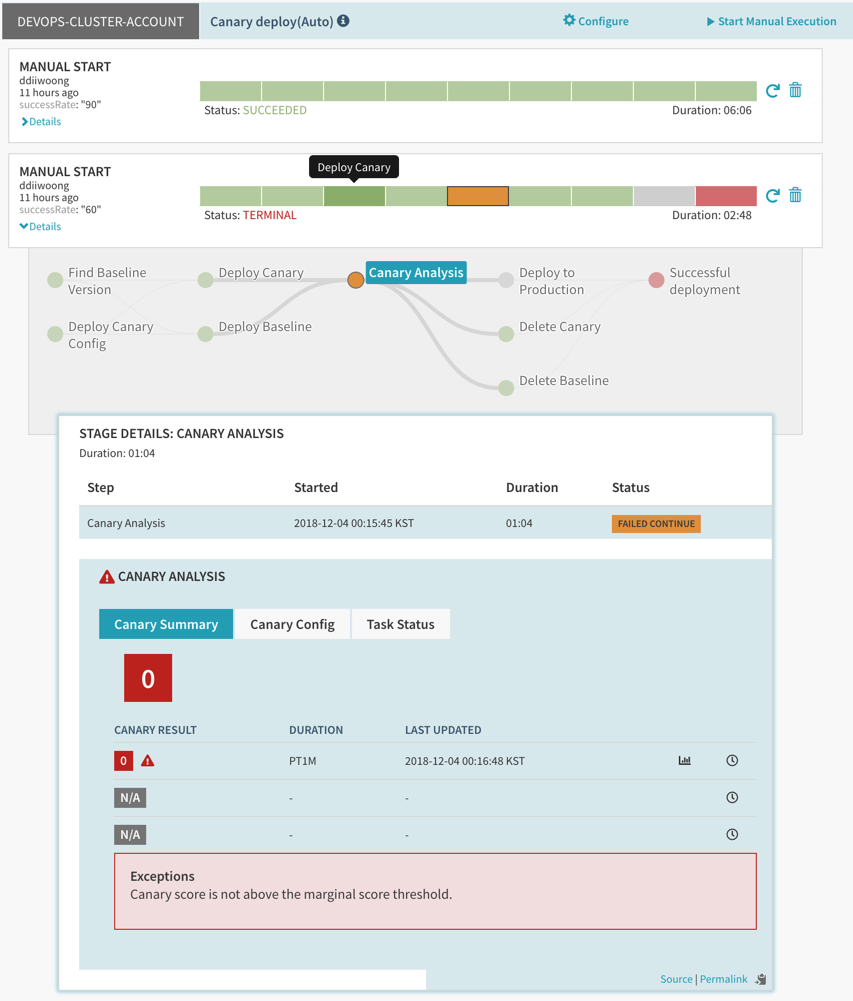
70 이상으로 설정하게 되면 Score 100점으로 정상 배포됨을 확인할 수 있다.
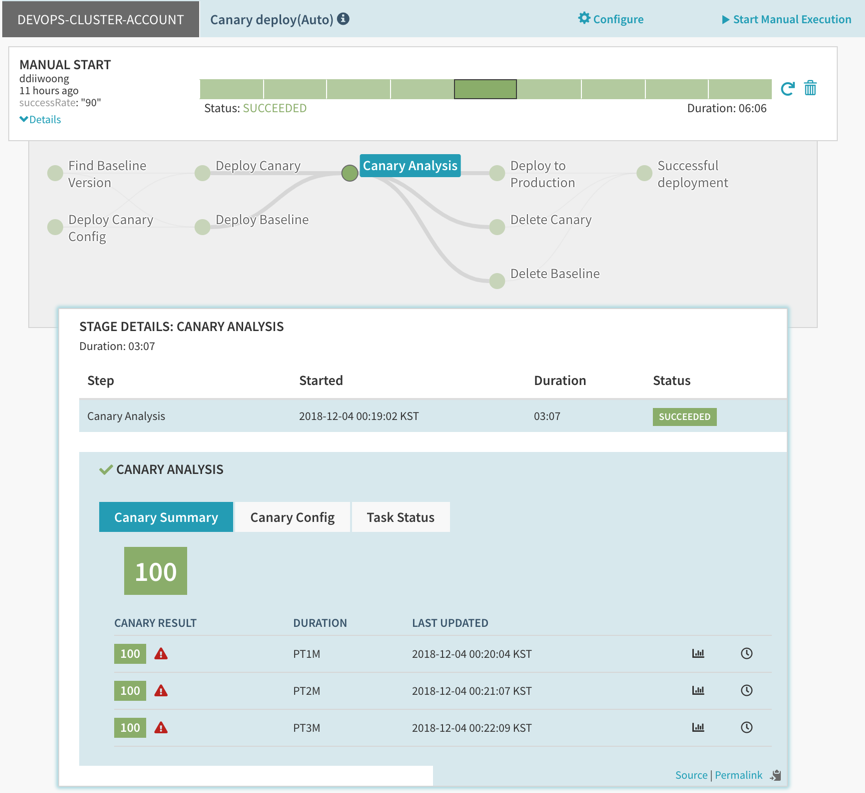
간단하게 Spinnaker 와 Prometheus Metric을 활용하여 Kayenta 기반 Canary 배포를 해봤다. 현재 Spinnaker 1.10에서 istio가 지원된다고 하니 다시 한번 확인하고 istio 기반 canary 배포와 함께 사용하는 방법을 더 연구해봐야 할 것 같다.
올해 AWS re:invent 끝나고 작년보다 큰 현자타임이 왔다. 오픈소스로 먹고사는 사람들의 기분은 다 비슷할거 같다고 생각이 든다. 12월 11일 부터 Kubecon이 열린다고 하니 Kubernetes 관련한 새로운 프로젝트와 기능들에 집중해서 남들보다 한발 나아가야하지 않을까? 오픈소스로 먹고사시는 분들 다들 힘냈으면 좋겠다.