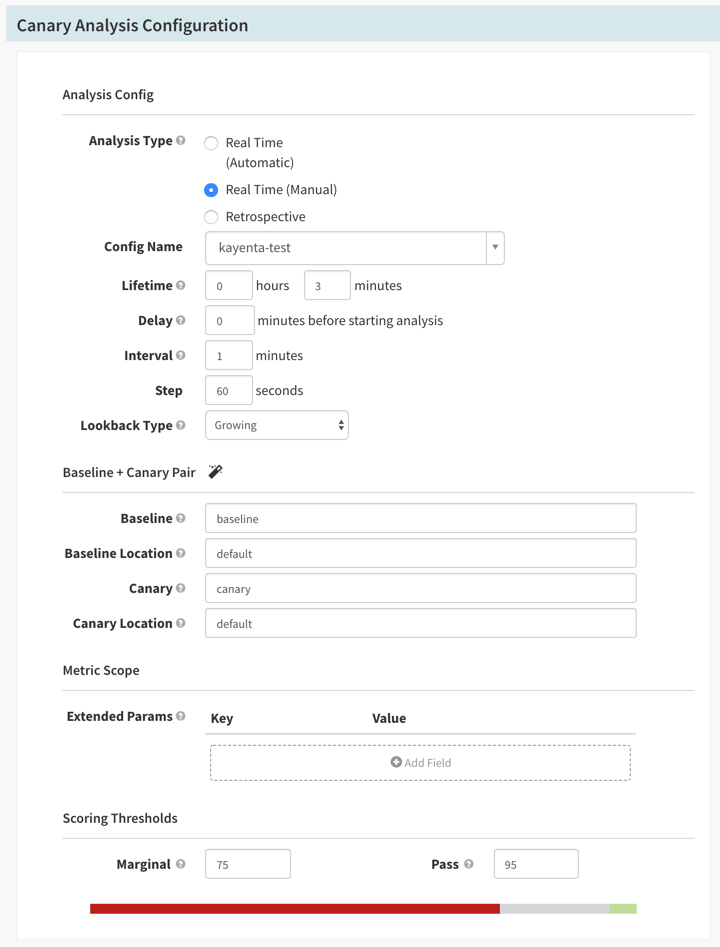
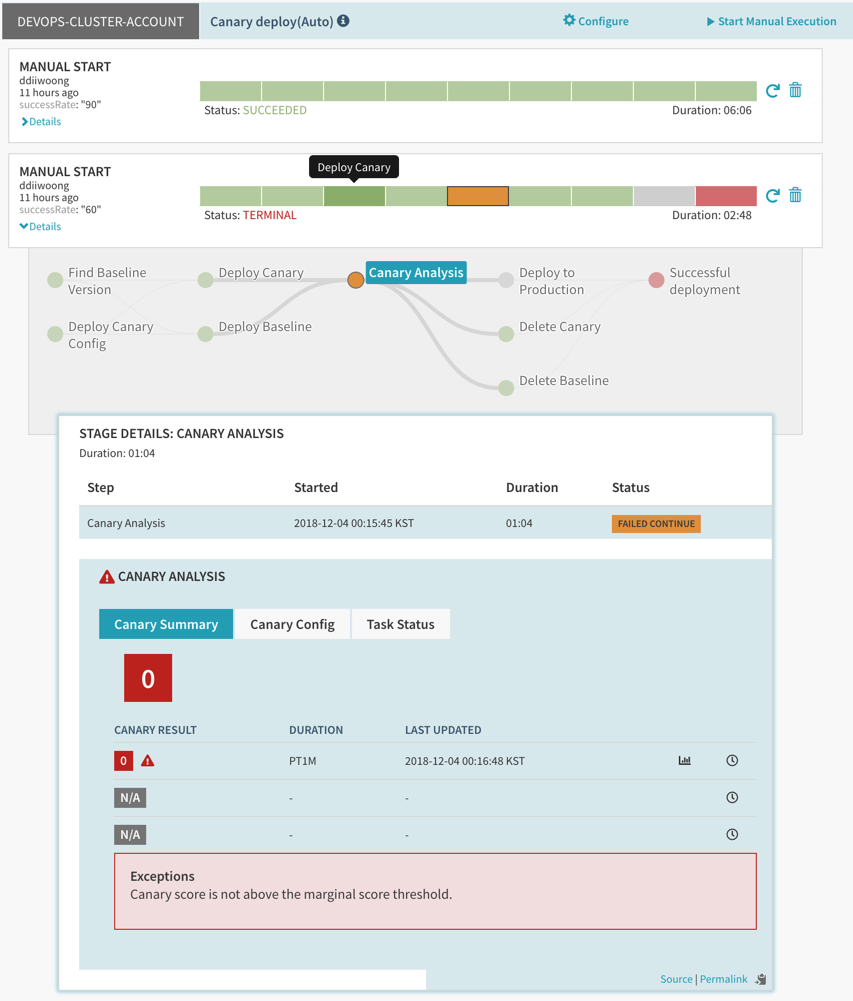
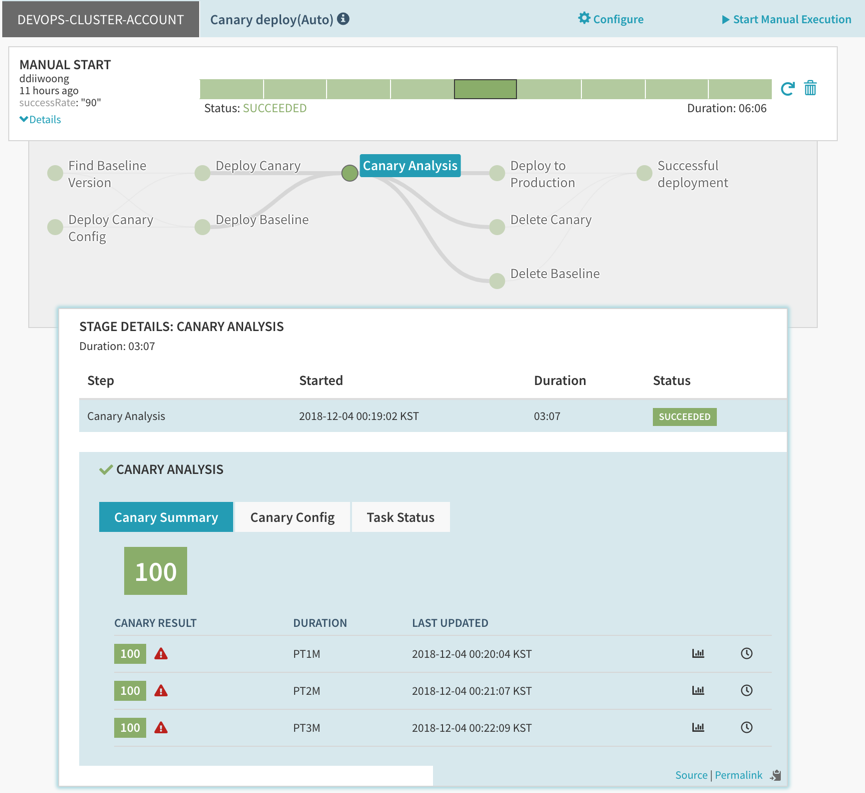
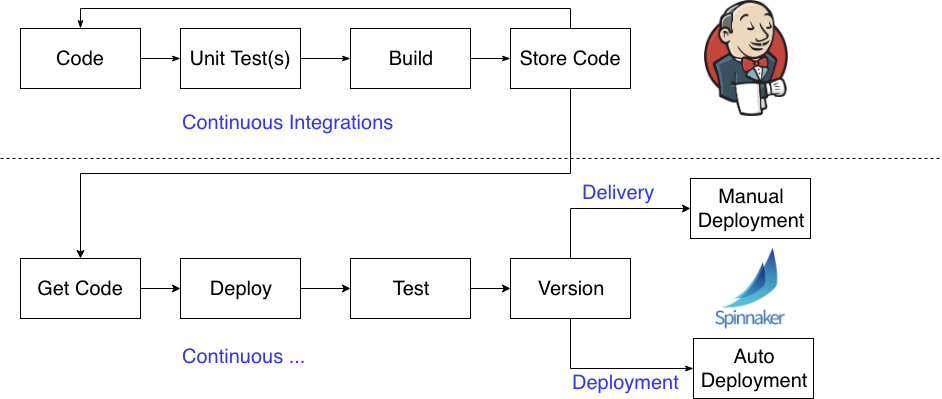
Knative with Gloo
Knative Routing
Knative는 앞에서도 몇번 언급하였지만 기본적으로 Routing을 사용하여 외부에 노출할 서비스들에 대한 HTTP Endpoint를 제공한다. 어떻게 보면 기본적으로 API Gateway 역할을 하기도 하고 Ingress 역할을 하기도 한다. 보통 Service mesh인 Istio를 사용하여 ingress를 구현하는것이 당연하다고 생각하기도 하지만 Istio의 모든 기능이 Knative에 필요하지는 않고 설치되는것 자체가 리소스 소모가 꽤 된다는것은 설치 해본사람은 알고 있을것이다.
Service
Kubernetes
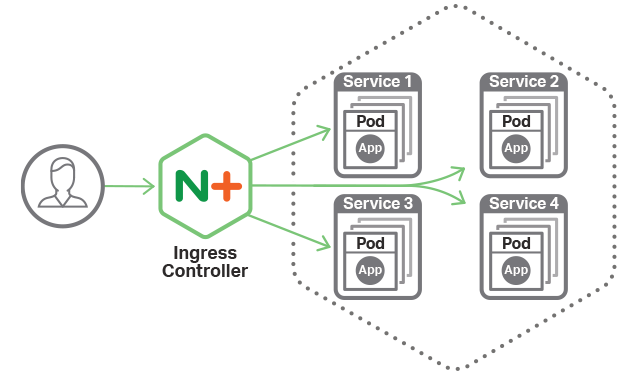
이미지출처 : https://www.nginx.com/blog/announcing-nginx-ingress-controller-for-kubernetes-release-1-3-0/
Kubernetes에서는 일반적으로 서비스 접속을 구현하게 되면 기본적으로 Pod와 Service를 생성하고 Ingress를 사용하여 클러스터 내부로 들어오는 트래픽을 처리하게 된다.
Knative

이미지출처 : https://blog.openshift.com/knative-serving-your-serverless-services/
Knative에서는 앞선 Knative 관련 포스팅에서도 설명했듯이 Automatic scaling up and down to zero 특성을 가지고 있기에 Pod가 최초 실행되어있지 않은 상태에서 트래픽이 들어오게 되면 Knative Serving Activator에 의해서 Pod가 없는 Revision을 �확인하고 Cold Start 형태로 프로비저닝하게 된다. 나는 이게 진정한 서버리스라고 생각하지만 주변에 반박하시는 분들도 간혹 있다.
이후 Pod가 Warm 상태가 되고 나면 Istio Route(Ingress Gateway)를 통해 트래픽이 Pod로 전달되어 통신이 이뤄지게 된다.
현재 Knative는 현재 Ingress Gateway 의존성을 가지고 있고 Envoy기반 Service Mesh인 Istio, Envoy기반 API Gateway인 Gloo 두가지 옵션으로 Ingress 구현이 가능하다.
Istio
Knative는 기본적으로 Ingress Gateway기능을 탑재하고 있는데 이는 Istio의 기능중 하나다.
Istio는 다음과 같은 Core Feature를 가진다. 상세한 내용은 https://istio.io/docs/concepts/what-is-istio/ 에서 확인하면 된다.
- Traffic management
- Security
- Policies and Telemetry
- Performance and Scalability
Istio는 48개의 CRDs(CustomResourceDefinition objects)를 가지고 있는데 이중 Knative Serving에서 사용하는건 VirtualService 단 하나다.
Gloo
Gloo는 Kubernetes-native ingress controller이자 Next Generation API Gateway 를 위해 시작된 프로젝트이다. 실제 Redhat에��서 Openshift기반 Microservice 및 Istio 개발업무를 하다가 최근에 solo.io의 CTO로 이직한 Christian Posta가 밀고 있는 프로젝트이기도 하다.
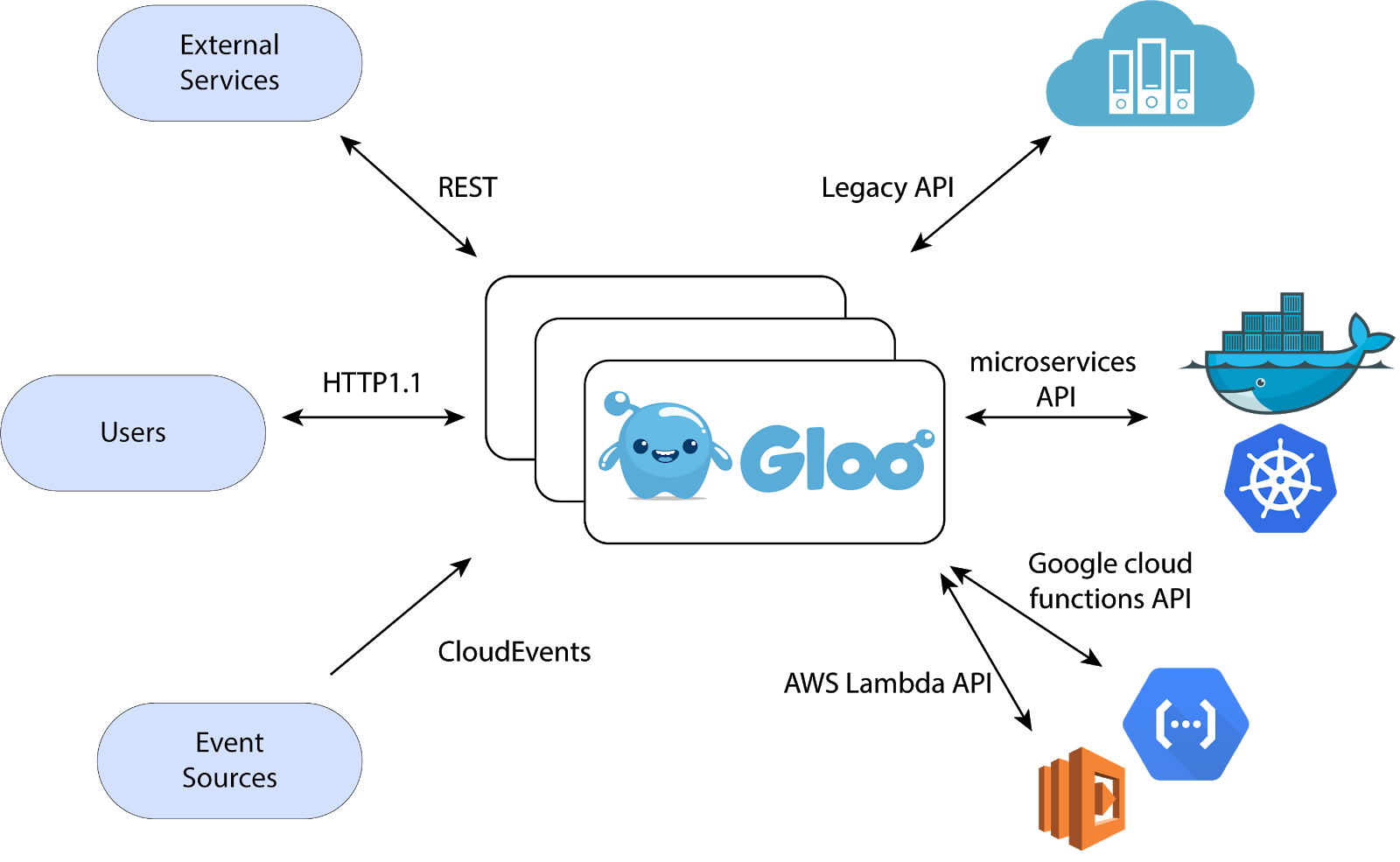
Gloo는 Envoy Proxy 기반으로 동작하며
기존 Legacy부터 Container서비스, FaaS(AWS Lambda, Azure Functions, GCP Functions)영역의 Application들을 REST, gRPC, SOAP, Web Socker기반으로 Aggregate 해서 Function 기반 추상화를 구현해 주는 오픈소스 프로젝트라 정의 할 수 있다.
Istio의 Ingress기능외의 여러가지 부가 기능(Telemetry, Security, Policy Enforcement)들은 Knative에서는 필요로 하지 않는다.
Knative API Gateway 로서 Istio가 아닌 Gloo가 조금더 경량화된 대안으로 결정되었고 Gloo를 통해 Knative 설치가 가능하게 되었다. 단, Knative Eventing 컴포넌트는 현재 지원하지 않는다고 한다.
Install Knative with Gloo
간단하게 gloo와 Knative 설치를 해보자.
Requirements
- Kubernetes cluster v1.11 or newer
- Enable MutatingAdmissionWebhook admission controller
- kubectl v1.10 or newer
- Bash in Mac or Linux
Install Glooctl
gloo CLI (glooctl) Download
https://github.com/solo-io/gloo/releases
또는 직접 Download
$ curl -sL https://run.solo.io/gloo/install | sh
Attempting to download glooctl version v0.8.1
Downloading glooctl-darwin-amd64...
Download complete!, validating checksum...
Checksum valid.
Gloo was successfully installed 🎉
Add the gloo CLI to your path with:
export PATH=$HOME/.gloo/bin:$PATH
Now run:
glooctl install gateway # install gloo's function gateway functionality into the 'gloo-system' namespace
glooctl install ingress # install very basic Kubernetes Ingress support with Gloo into namespace gloo-system
glooctl install knative # install Knative serving with Gloo configured as the default cluster ingress
Please see visit the Gloo Installation guides for more: https://gloo.solo.io/installation/
PATH 등록
$ export PATH=$HOME/.gloo/bin:$PATH
gloo CLI 확인
$ glooctl --version
glooctl version 0.8.1
GCP 무료플랜으로 3-node 클러스터를 생성한다.
$ gcloud container clusters create gloo \
--region=asia-east1-a \
--cluster-version=latest \
--machine-type=n1-standard-2 \
--enable-autorepair \
--num-nodes=3
cluster 생성된것을 확인하고 cluster-admin 권한을 할당한다.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
gke-gloo-default-pool-f6bcc479-f8v9 Ready <none> 9m v1.11.7-gke.6
gke-gloo-default-pool-f6bcc479-fl78 Ready <none> 9m v1.11.7-gke.6
gke-gloo-default-pool-f6bcc479-gfgw Ready <none> 9m v1.11.7-gke.6
$ kubectl create clusterrolebinding cluster-admin-binding \
> --clusterrole=cluster-admin \
> --user=$(gcloud config get-value core/account)
Your active configuration is: [cloudshell-25974]
clusterrolebinding.rbac.authorization.k8s.io "cluster-admin-binding" created
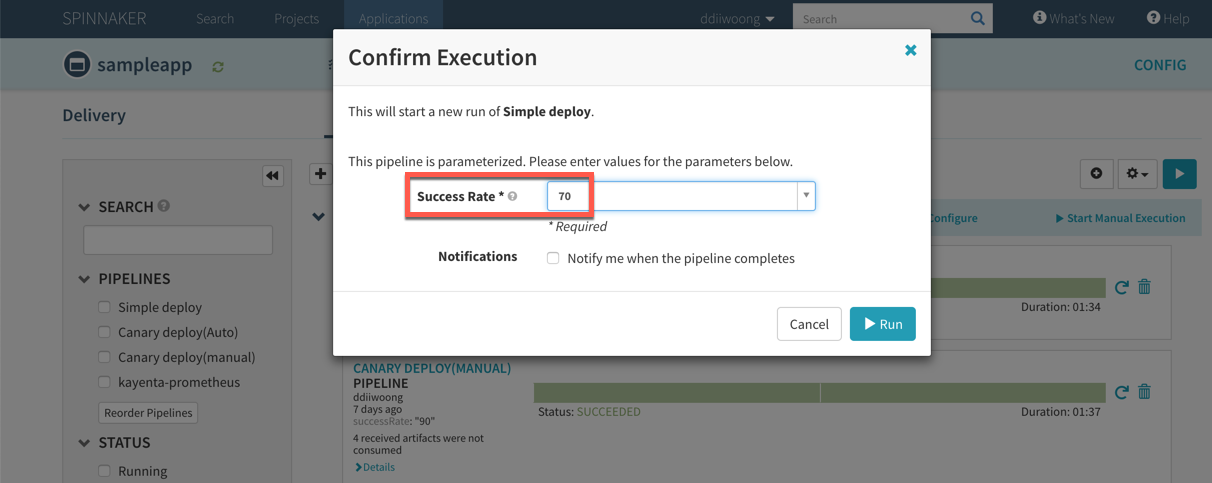
Gloo와 Knative 설치를 한다. 미리 glooctl install knative --dry-run 으로 전체 manifest를 확인할 수 있다.
$ glooctl install knative
위에서 설치 과정은 생략했지만 Istio에 비해 CRD 개수가 적은 것을 알수있다. 또한 설치된 컴포넌트 역시 Istio에 비해서 간소화된 것을 알수 있다.
$ kubectl get pods --namespace gloo-system
NAME READY STATUS RESTARTS AGE
clusteringress-proxy-59fd6fb56-dmwwm 1/1 Running 0 7m
discovery-779884d4cc-xlql2 1/1 Running 6 7m
gloo-844fc79445-f4zvg 1/1 Running 6 7m
ingress-7d75c99874-s4m76 1/1 Running 6 7m
$ kubectl get pods --namespace knative-serving
NAME READY STATUS RESTARTS AGE
activator-746f6bb684-49tfh 1/1 Running 0 12m
autoscaler-955f679cd-tx5vw 1/1 Running 0 12m
controller-7fc84c6584-jbn69 1/1 Running 0 12m
webhook-7797ffb6bf-6pgsw 1/1 Running 0 12m
이전 포스팅에서도 사용했던 gcr.io/knative-sample/helloworld-go 이미지를 활용하여 샘플앱 Knative Service를 만든다.
service.yaml
$ vi service.yaml
apiVersion: serving.knative.dev/v1alpha1
kind: Service
metadata:
name: helloworld-go
namespace: default
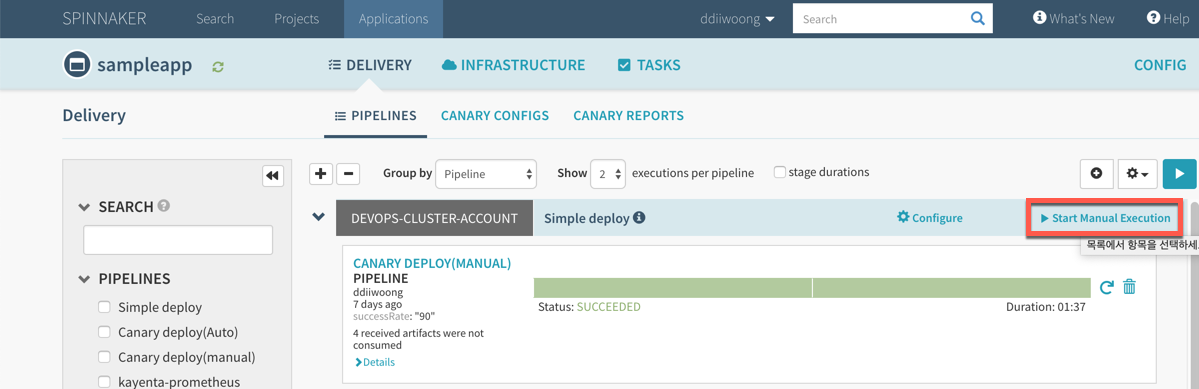
spec:
runLatest:
configuration:
revisionTemplate:
spec:
container:
image: gcr.io/knative-sample/helloworld-go
env:
- name: TARGET
value: "Go Sample v1"
$ kubectl apply --filename service.yaml
service.serving.knative.dev "helloworld-go" created
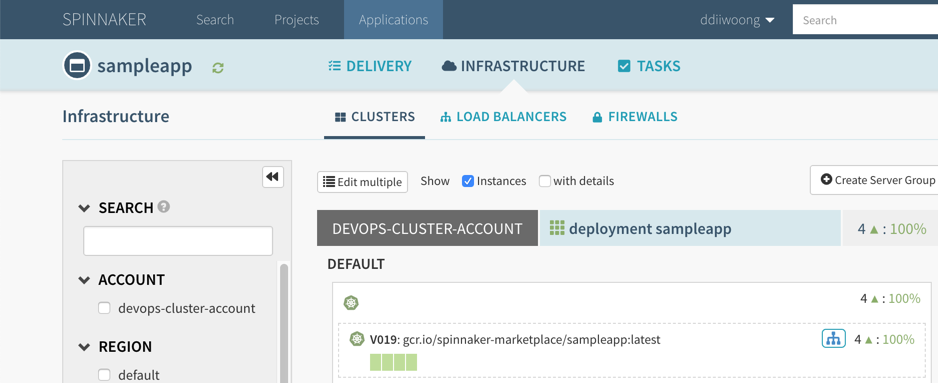
앞에서도 설명했지만 Automatic scaling up and down to zero 으로 Cold Start가 되고 잠시후에 아래와 같이 Knative Service를 확인할 수 있다.
$ kubectl get ksvc helloworld-go -n default --output=custom-columns=NAME:.metadata.name,DOMAIN:.status.domain]($ kubectl get ksvc helloworld-go -n default --output=custom-columns=NAME:.metadata.name,DOMAIN:.status.d
omain
NAME DOMAIN
helloworld-go helloworld-go.default.example.com
Gloo Ingress를 확인한다. GKE에서 설치했기 때문에 자동으로 LoadBalancer가 연동되어 있는것을 확인할 수 있다.
$ kubectl get svc -n gloo-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
clusteringress-proxy LoadBalancer 10.3.244.54 34.**.**.54 80:30978/TCP,443:32448/TCP 39m
gloo ClusterIP 10.3.243.231 <none> 9977/TCP 39m
$ glooctl proxy url --name clusteringress-proxy
http://34.**.**.54:80
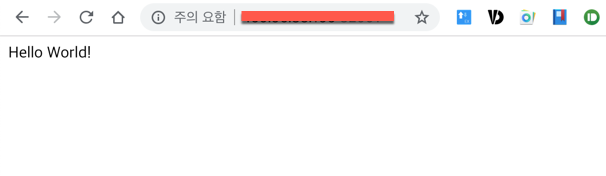
위에서 얻은 두가지 정보로 생성된 app을 테스트한다. Cold Start(default timeout 5분) 때문에 응답이 늦어질 수도 있지만 잠시 기다리면 응답을 확인할 수 있다.
$ curl -H "Host: helloworld-go.default.example.com" http://34.**.**.54:80
Hello Go Sample v1!
물론 Revision이나 Route를 활용하여 Knative의 기능에 대해서도 확인이 가능하다.
정리
Gloo는 Knative ClusterIngress CRD를 기반으로 동작하는 Istio의 대안으로서 가능성을 보여주고 있다. 이외에도 The Service Mesh Orchestration Platform SuperGloo, Debugger for microservices Squash 등 다양한 Mesh Layer기반�의 오픈소스들을 확인할수 있다. 또다른 스쳐지나갈수도 있는 오픈소스일수도 있겠지만 현재 개발되는 로드맵(https://www.solo.io/)을 보면 Knative가 고도화되는 여정에 같이 가는 모습을 확인할 수 있다.
next-generation API Gateway로서 다양한 프로토콜을 지원하기 때문에 (HTTP1, HTTP2, gRPC, REST/OpenAPISpec, SOAP, WebSockets, Lambda/Cloud Functions) 더욱더 Microservices 및 Serverless Workload를 수행하기에 더욱 적합한 오픈소스로 보인다.
다음 주제
현재 해보고 싶은것은 베어메탈 Kubernetes Cluster기반 BGP로 동작하는 MetalLB나 Cillium on AWS 인데 시간나는 대로 테스트 해봐야 겠다.