2019 Retrospective
· 4 min read
또 한해가 지나갔다. 2019년 한일 정리하면서 2020년 플랜 기록용으로 끄적거려본다.
-
Work
- 18년도 까지 서비스 개발을 맡았지만 갑작스럽게 부서 이동으로 인해 FaaS 개발을 손을 떼고 신규 부서로 이전하게 되었다. 작년 초에도 큰 변화였는데 이번에도 더 큰 변화였다.
- 문제는 개발보다는 기획쪽에 더 가까운 업무였고 데이터 분석 관련한 플랫폼을 개발하는 TF에 포함되게 되었다. 머신러닝, 데이터 엔지니어링과는 담을 쌓았었지만 어쩔수 없이 분석 관련하여 과제 수행
- 1-3월에는 주로 모빌리티 관련 에코파트너들과 협력 및 사업개발을 위한 기술검토 및 검증.
- 4-6월에는 그룹 관계사들의 데이터레이크에 대한 정의와 설계, 플랫폼 구현을 위한 Design-Thinking, 서비스 포털 기획 등을 수행하고 그룹 관계사들의 데이터레이크에 대한 정의와 설계 진행.
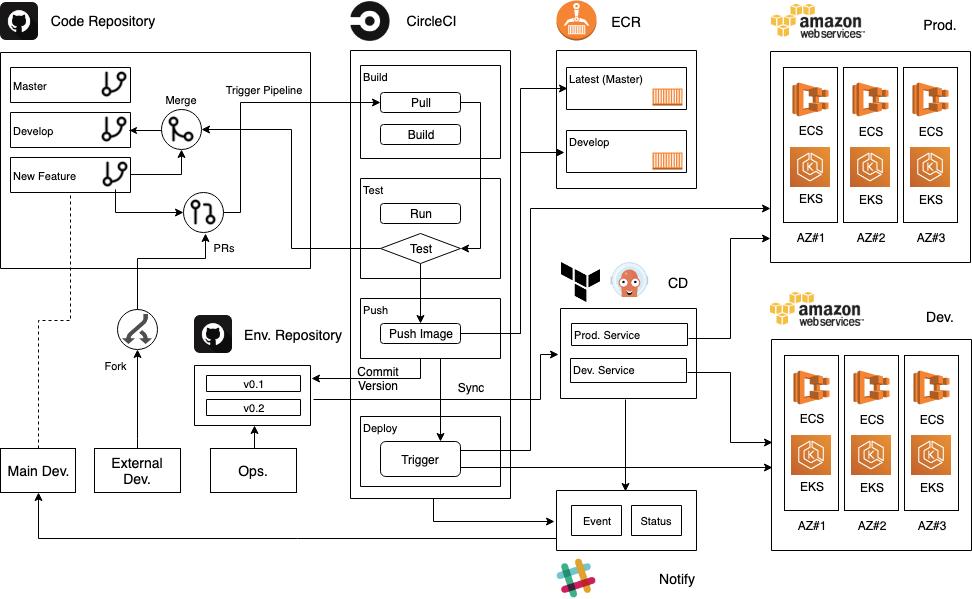
- 7-9월에는 서비스 포털 개발을 위한 CI/CD 선정 및 devops 파이프라인 구성, 데이터 preparation 툴 검토 및 AWS Managed 서비스 검증 및 구현 업무를 수행했다. 또한 프론트엔드 서비스 처리를 위한 람다함수 개발 및 documents 레포지토리 구축 진행.
- 10-12월까지는 서비스 포털 오픈 및 고도화, 다음 단계 서비스 기획 수행함.
-
Main Tools
- Python, Node.js, Java(Springboot)
- AWS - ECS, Lambda, CloudFront, Athena, Glue, S3, SageMaker
- IBM Cloud - Object Storage
- Github Team
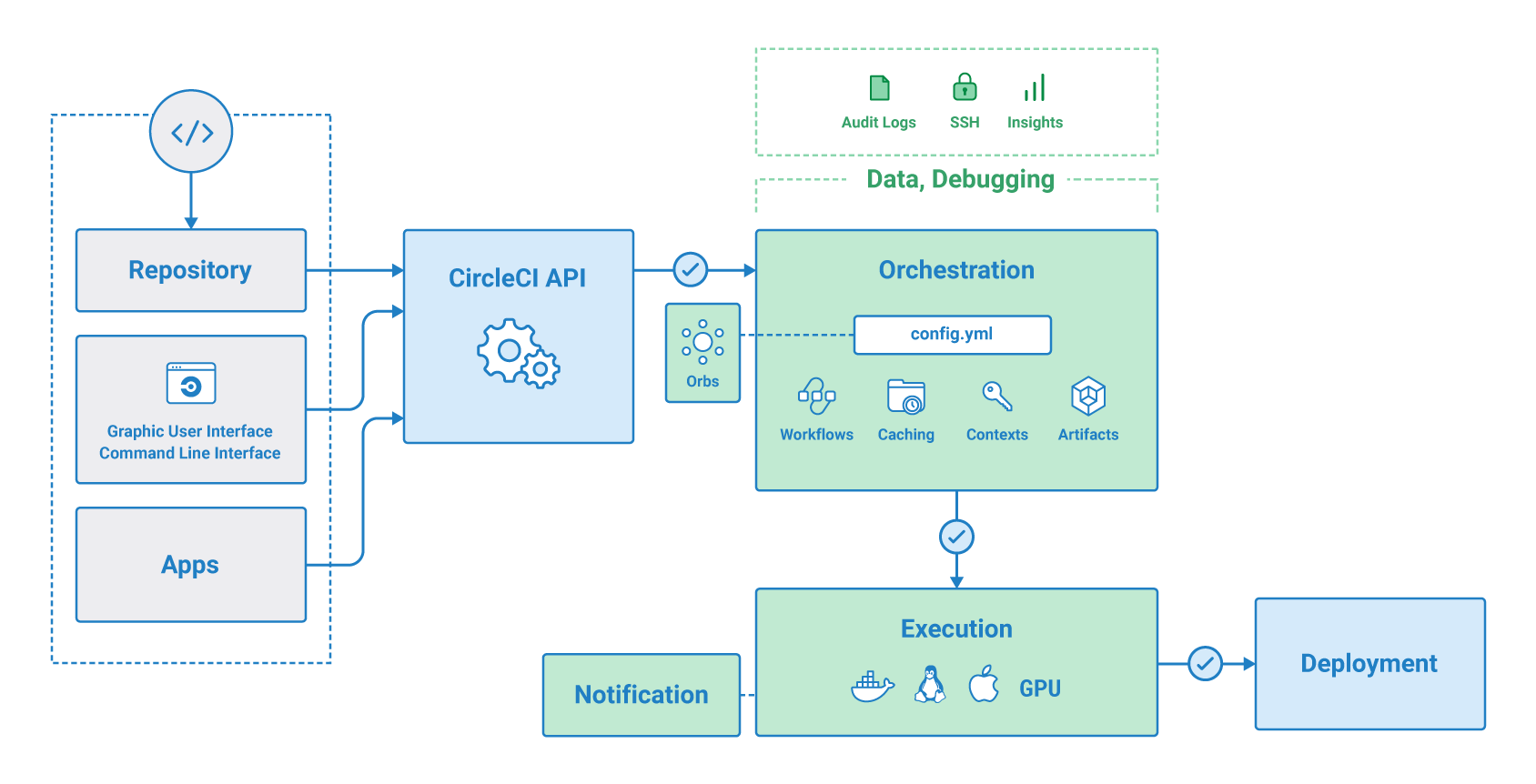
- CircleCI, Github Action
-
Side (Community포함)
- 번역 : 프로메테우스 인프라스트럭처 모니터링 [가상머신, 컨테이너 환경의 프로메테우스 모니터링 실습과 활용]
- 블로그 포스팅 - 13회 (목표 25회 미달성)
- 사내 연구 과제 - 멀티클라우드 구현을 위한 IaC 연구 (5-10월)
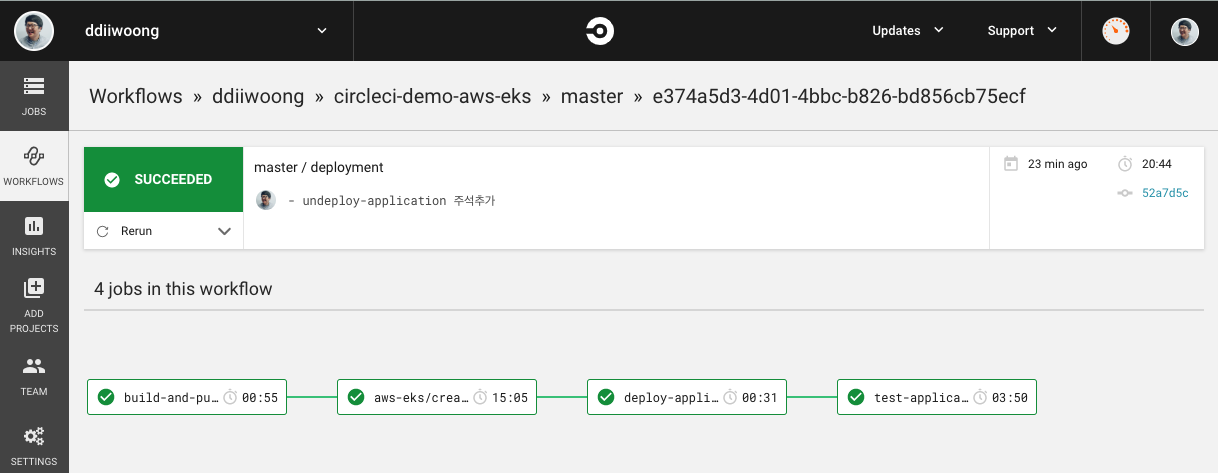
- Terraform, Terratest, Ansible, Kubespary, CircleCI 조합으로 하나의 파이프라인에서 Bastion 없이 멀티 클라우드(AWS, IBM, GCP) 환경에 Elastic 및 K8s 클러스터 배포 및 테스트 자동화 환경 구성
- Istio 스터디 (9-11월)
- 다양한 회사분들과 스터디 진행 (카카오뱅크, 이베이, 하이퍼커넥트)
- 다양한 경험을 들을수 있어서 좋은 경험!!
- 자료 : https://github.com/dev-chulbuji/istio-study
- 다양한 회사분들과 스터디 진행 (카카오뱅크, 이베이, 하이퍼커넥트)
- K8s Korea Group 모니터링 소모임 진행
- 1차 (4/25) SK u-tower
- 발표1 : OpenCensus with Prometheus and Kubernetes (김진웅)
- 발표2 - Service Mesh(Istio) Monitoring (나정호)
- 2차(6/4) 메가존
- 발표1 : 쿠버네티스 운영 관리 오픈소스: NexClipper 소개 (김진용)
- 발표2 : 난상토의 (모니터링, 아키텍처 경험 등 자유주제 공유, 토의)
- 1차 (4/25) SK u-tower
- AWS Korea User 소모임 참여
- 판교, 컨테이너, 서버리스, 데이터 사이언스, 머신러닝 스터디, 데브옵스
- CircleCI 밋업 참여
- 1차 (5/14), 2차 (8/27)
- Open Infrastructure & Cloud Native Days Korea 2019 참여 (7/18-19)
- Kubernetes Forum Seoul 참여 (12/9)
- CFP 탈락 ㅠㅠ
- 개인 서버, NAS 2대 Shutdown (전기세 압박에서 해방됨)
- G Suite Business 로 갈아탐
- 미디어 환경 개편
- 스마트TV 직구 (75SM8670PUA)
- PS4 구매 (닌텐도 스위치, Xbox 기존보유)
- K3s Home Lab구성 및 이더패드 서비스 운영
- 1.16 클러스터 : 1 Master, 3 Workers
- 독서
- 20권 내외 (기술서 포함)
- 교육
- Google Study Jam - 클라우드 4회, 머신러닝 4회 수료
- Udemy - CKA, CKAD
- Elasticsearch Engineer I, II
-
Speak
- 2018년에 비해 대외 발표가 많이 적었다. 실제 K8s 관련 업무를 하지 않아 그런 듯 하다.
- 4월 AWS Korea User Group 판교소모임
- 4월 Kubernetes Korea Group 모니터링 소모임
- 4월 Google Cloud Next ‘19 Extended Korea
- 6월 Korea DevOps MeetUP ‘19 - 4월 발표 수정
- 7월 CircleCI Korea User Group 2nd Meetup
- 9월 AWS Korea User Group 판교소모임
- 11월 사내 Open Tech Lounge 발표
- 멀티클라우드 구현을 위한 IaC 연구
-
2020 목표
- 커뮤니티 활동은 최대한 줄이기 (필수적인 부분만)
- SRE group 활성화 방안 고민
- 밋업, 세미나 관련 캘린더 연동 자동화 방안 고민
- 번역 및 책 쓰는건 고민을 더...
- Level Up
- 영어!! - 발표까지
- Full-Stack ??
- 머신러닝, 딥러닝
- ELK 쿼리 잘짜기
- NoSQL
- 기존업무 K8s 전환 및 고도화
- 서버리스, 매니지드 방향으로
- 사이드 프로젝트
- 홈 미디어 관리 고도화 (Plex)
- nextcloud 서비스 오픈 (지인 대상)
- 모바일 웹앱 3개 만들기 (미디어 관리, 코믹 뷰어, 스트리밍)
- 오픈소스 기여
- 커뮤니티 활동은 최대한 줄이기 (필수적인 부분만)