CircleCI로 AWS BATCH(ECS) CI/CD Pipeline 구성
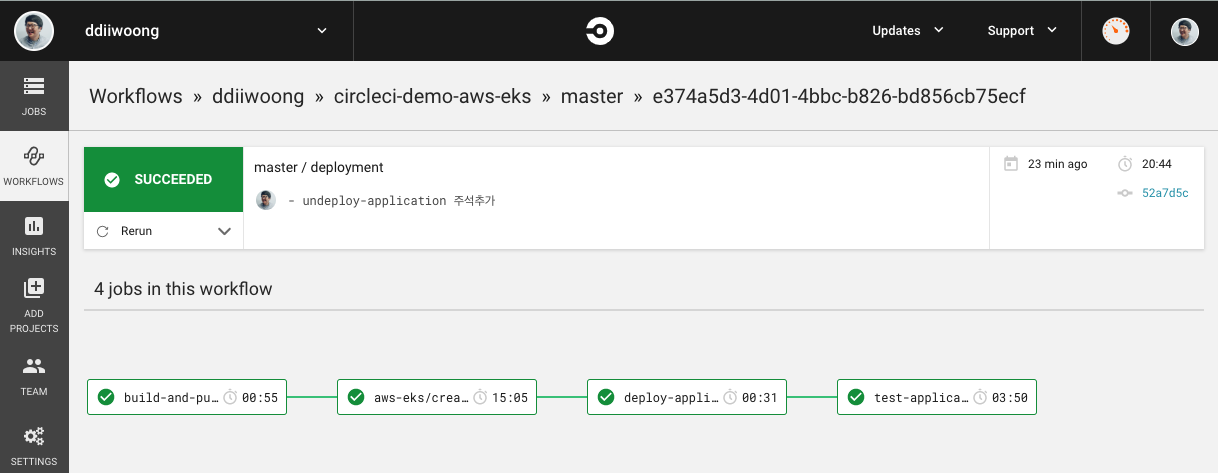
이전 포스팅에서 EKS 클러스터와 어플리케이션 배포 및 테스트를 간단하게 해봤다. 이번에는 AWS ECS 또는 AWS Batch Application을 CircleCI를 통해 배포 및 업데이트 하는 것을 알아본다.
Application 요구사항
기본적으로 현재 업무 중에 IBM클라우드에서 AWS로 데이터를 가져와야 하는 업무가 생겨서 시작되었고 정기적으로 매일 새벽에 크롤링(Pull)방식으로 데이터를 복제해야하는 Use-Case를 구현해야 했다.
CI/CD Pipeline구성이 주 목적으로 Application구현은 포스팅 내용에서 제외하였다.
기본 요구사항
- Github Account
- CircleCI Account (Github Auth)
- AWS ECR(Elastic Container Registry)
- AWS Batch(ECS)
CI/CD 구성안
실제 프로젝트에 적용할 구성안이다.
기본적으로 모든 구성은 최대한 비용이 들지 않고 AWS 종속성을 제거한 방법으로 구성하였다.
- Code Repository : Github
- CI : CircleCI
- Registry : AWS ECR
- CD : CircleCI
- Target : AWS Batch(ECS)
- Notification : Slack
이번 데모에서는 다음과 같은 시나리오로 진행하려고 한다.
- Terraform으로 AWS Batch 생성
- Github에 수정된 Batch Code(Shell Script) Commit & Triggering CircleCI
- Docker Build & AWS ECR로 Push
- S3로 myjob shell 파일 복사
- AWS Batch(ECS) Job Definition 변경(Change Image)
AWS Batch
기본적으로 Batch 컴퓨팅을 목적으로 하는 서비스로 컴퓨팅 타입을 Fargate 또는 EC2 중 하나를 선택하여 동적으로 프로비저닝하는 서비스이다.
초기 설정이 번거롭긴 하지만 한번 구성하고 나면 별도 관리가 필요없고 Batch작업이 발생하는것과 컨테이너 이미지 보관비용 이외에는 추가 비용이 발생하지 않기 때문에 비용측면에서 장점이 있는 서비스이다.
위에서 이야기한 정기적으로 새벽마다 크롤링(Pull)방식으로 데이터를 복제해야하는 Use-Case를 구현하는것이 적당한 워크로드 구현방법이라 생각했기 때문에 AWS Batch 서비스를 사용하게 되었다.
간단한 Batch demo는 https://github.com/awslabs/aws-batch-helpers/에서 확인이 가능하며 CircleCI연동을 위해 Fork후 진행하였다.
Demo Repository : https://github.com/ddiiwoong/aws-batch-helpers/
CircleCI
모든 Pipeline은 CircleCI기반으로 작성하였다. 혹자는 AWS Code Commit, Pipeline을 사용하지 않느냐고 문의하시는 분들도 있는데 다음과 같은 이유로 CircleCI를 선택하였다.
- Fully Managed (Serverless)
- AWS 종속성 최소화
- Git, Registry, CD영역의 확장성 고려
- AWS Console 접속 최소화
- 쉽고 단순하게 빌드 환경구성
- 소규모 프로젝트 빠르게 시작 가능
Amazon Elastic Container Registry (ECR)
개인적으로 Registry는 구축형보다는 Managed서비스를 사용하는것이 좋다고 보기 때문에 Webhook을 Native하게 지원하는 DockerHub도 대체 가능하다고 생각한다.
- Fully Managed
- Security (IAM) 연동
- CircleCI Orbs 제공
- EKS, ECS 연동 용이
Terraform
https://www.terraform.io/docs/providers/aws/index.html
선언적 인프라스트럭처 관리 도구로 많이 사용하고 있는 도구이며 Docs와 블로그 자료가 많은 관계로 따로 설명하지 않겠다.
이번 포스트에서는 AWS Batch를 생성하는 영역을 Terraform이 담당한다.
CircleCI Config 작성
version: 2.1
orbs:
aws-ecr: circleci/aws-ecr@6.1.0
aws-ecs: circleci/aws-ecs@0.0.8
aws-s3: circleci/aws-s3@1.0.11
aws-cli: circleci/aws-cli@0.1.13
jobs:
sh-s3-upload:
docker:
- image: 'circleci/python:2.7'
steps:
- checkout
- aws-s3/copy:
from: ./myjob.sh
to: 's3://batch-ecr-test/myjob.sh'
deploy-batch:
executor: aws-cli/default
steps:
- checkout
- aws-cli/install
- run:
name: Update AWS Batch Job
command: |
aws batch register-job-definition --job-definition-name fetch_and_run --type container --container-properties '{ "image": "823928750534.dkr.ecr.ap-northeast-2.amazonaws.com/fetch_and_run:v20190623", "vcpus": 1, "memory": 512}'
workflows:
build-and-deploy:
jobs:
- aws-ecr/build-and-push-image:
repo: $AWS_RESOURCE_NAME_PREFIX
tag: v20190623
- sh-s3-upload:
name: sh-s3-upload
requires:
- aws-ecr/build-and-push-image
- deploy-batch:
name: deploy-batch
requires:
- sh-s3-upload
단계별 설명을 위해 부분적으로 설명하도록 하겠다.
-
Terraform으로 Batch 배포
resource "aws_batch_compute_environment" "default"{
compute_environment_name = "env_fetch_and_run"
compute_resources {
instance_role = "arn:aws:iam::823928750534:instance-profile/ecsInstanceRole"
instance_type = [
"optimal",
]
desired_vcpus = 1
max_vcpus = 1
min_vcpus = 0
security_group_ids = [
"sg-0632cf81b5c4dff17"
]
subnets = [
"subnet-0c4f8135b536e8fab",
"subnet-0a261950d894cf27e"
]
type = "EC2"
}
service_role = "arn:aws:iam::823928750534:role/service-role/AWSBatchServiceRole"
type ="MANAGED"
}Batch Computing 환경을 구성하게 되는데
"aws_batch_compute_environment"를 사용한다.- compute_environment_name : (필수) 컴퓨팅 환경 이름
- compute_resources.instance_role : (필수) EC2에 적용되는 Role
- compute_resources.instance_type : (필수) 사용 가능한 instance 유형
- compute_resources.desired_vcpus : (옵션) 원하는 CPU수
- compute_resources.max_vcpus : (필수) 최대 CPU수
- compute_resources.min_vcpus : (필수) 최소 CPU수
- compute_resources.security_group_ids : (필수) EC2에 적용되는 Security Group
- compute_resources.subnets : (필수) Subnets 목록
- compute_resources.type : (필수) EC2를 기반으로 생성, SPOT instance 사용가능
- service_role : (필수) AWS Batch가 다른 AWS 서비스를 호출 할수있게 해주는 IAM Role(ARN)
- type : (필수) MANAGED나 UNMANAGED를 선택할 수 있고, MANAGED의 경우 compute_resources에 세부 사항을 설정할 수 있다.
resource "aws_batch_job_definition" "default" {
name = "fetch_and_run"
type = "container"
container_properties = <<CONTAINER_PROPERTIES
{
"command": [],
"image": "823928750534.dkr.ecr.ap-northeast-2.amazonaws.com/fetch_and_run:v20190623",
"vcpus": 1,
"memory": 512,
"volumes": [],
"environment": [],
"mountPoints": [],
"ulimits": []
}
CONTAINER_PROPERTIES
}Job Definition 정의("aws_batch_job_definition")에서는 Resource spec 및 Command(Docker RUN), Container IMAGE 등을 선언하게 된다.
- name : (필수) Job Definition 이름
- type : (필수) Job Definition 유형, ECS로 처리하기 위해 container로 선택
- container_properties : (선택) JSON 형태로 작성하는 container 속성정보 (Image, Resources, Command, MountPoint 등)
-
.circleci/config.yml에 CircleCI 버전 명시 및 관련 orb(ecr,ecs,s3,cli) 추가
기본적으로 2.1로 설정을 해야 ecs, eks orb 사용이 가능하다.version: 2.1
orbs:
aws-ecr: circleci/aws-ecr@6.1.0
aws-ecs: circleci/aws-ecs@0.0.8
aws-s3: circleci/aws-s3@1.0.11
aws-cli: circleci/aws-cli@0.1.13 -
workflow 구성
build-and-push-image->sh-s3-upload->deploy-batch순으로 순차적으로 pipeline구성을 하였다.workflows:
build-and-deploy:
jobs:
- aws-ecr/build-and-push-image:
repo: $AWS_RESOURCE_NAME_PREFIX # data-crawler-test
tag: v20190623
# create-repo: true
# dockerfile: Dockerfile
- sh-s3-upload:
name: sh-s3-upload
requires:
- aws-ecr/build-and-push-image
- deploy-batch:
name: deploy-batch
requires:
- sh-s3-upload기본적으로 CircleCI에서는 orb job을 [orb name]/[predefined-job] 형식으로 선언한다.
I. 첫번째 step에서는 container image를 build하고 push하는 Job을 수행하므로
aws-ecr/build-and-push-image을 선언한다.
자세한 내용은 https://circleci.com/orbs/registry/orb/circleci/aws-ecr를 확인하자.II. 두번째 step에서는 S3에 배치스크립트를 올리는 Custom Job을 수행한다. Job은 Step의 모음으로 선행되어야할 Job은 상위에
requires:에서 선언하면 된다.III. 세번째 step에서는 AWS Batch job definition의 container image를 교체(revision 변경)하는 Custom Job을 수행한다.
-
custom job 구성 Workflow에서 선언한 Custom Job의 상세 definition을 기재한다.
jobs:
sh-s3-upload:
docker:
- image: 'circleci/python:2.7'
steps:
- checkout
- aws-s3/copy:
from: ./myjob.sh
to: 's3://batch-ecr-test/myjob.sh'
deploy-batch:
executor: aws-cli/default
steps:
- aws-cli/install
- run:
name: Update AWS Batch Job
command: |
aws batch register-job-definition --job-definition-name fetch_and_run --type container --container-properties '{ "image": "823928750534.dkr.ecr.ap-northeast-2.amazonaws.com/fetch_and_run:v20190623", "vcpus": 1, "memory": 512}'I.
sh-s3-upload에서는aws-s3/copy를 사용하여 원하는 S3버킷에 사용할 스크립트를 업로드 한다.checkout에서는 현재 상태의 git repo를 clone하게 된다.II.
deploy-batch에서는aws-cli/install를 사용하여 기존에 작성한 Batch Job definition을 awscli로 원하는 새로운 image로 업데이트 하게 된다.
CircleCI 실행
빌드 및 배포과정을 간단하게 설명하면 코드가 업데이트되면 CircleCI는 해당 저장소의 .circleci/config.yml 을 기준으로 빌드 및 배포를 시작하게 된다.
README.md에 Build Status Badge 달기
https://circleci.com/docs/2.0/status-badges/
![]() 위 링크와 설정을 참고하여 아래 그림과 같이 Build Statud Badge를 달 수 있다.
위 링크와 설정을 참고하여 아래 그림과 같이 Build Statud Badge를 달 수 있다.
![]()
정리
이번에는 CircleCI를 가지고 AWS Batch job을 구성하는 데모를 진행하였다.
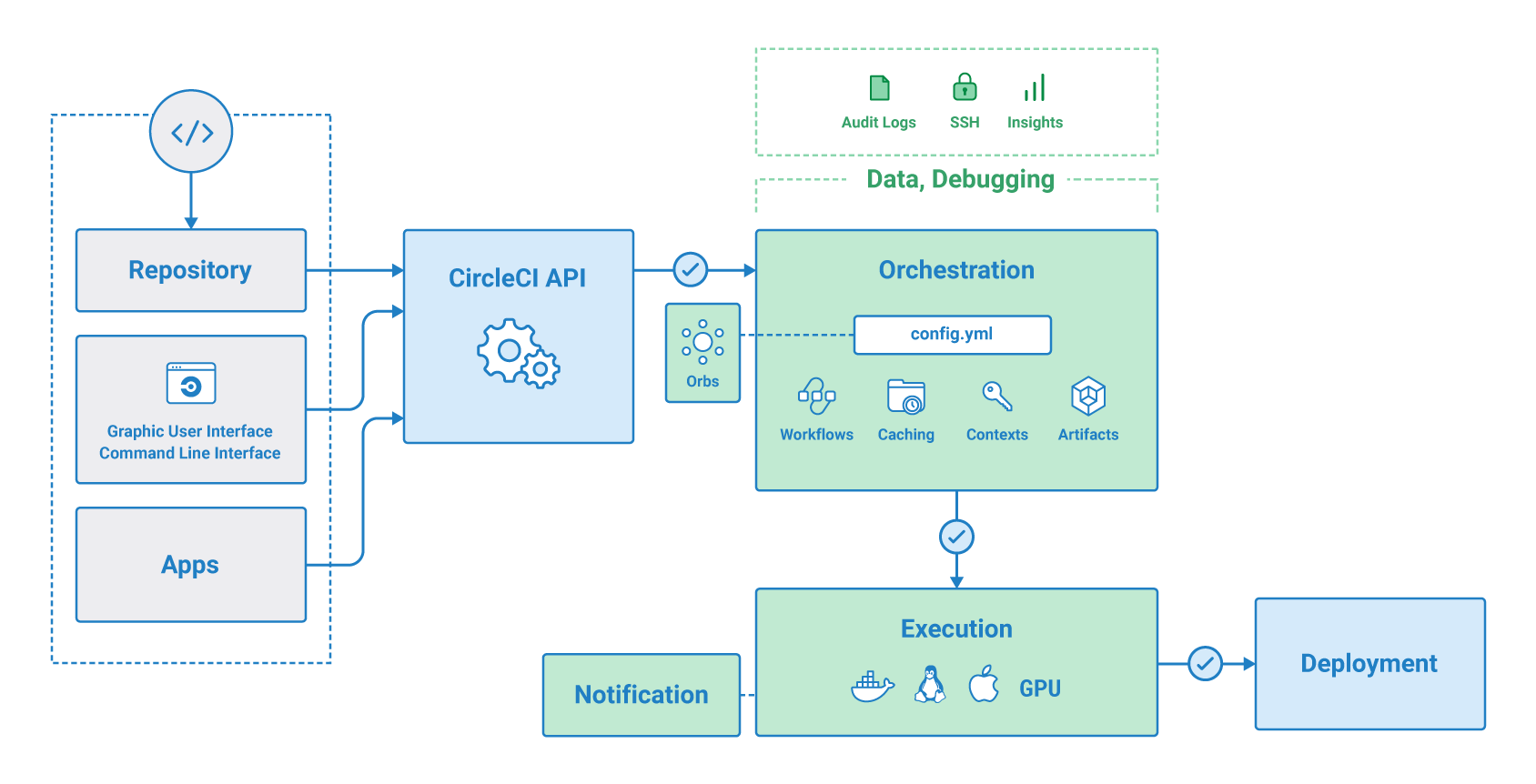
얼마전인가에도 어형부형님께서도 언급하신 선언적인 구성 기반에 최대한 serverless 환경에서의 배포를 추구하게 되다 보니 아래와 같은 CI/CD Pipeline 시나리오를 구상하게 되었다.
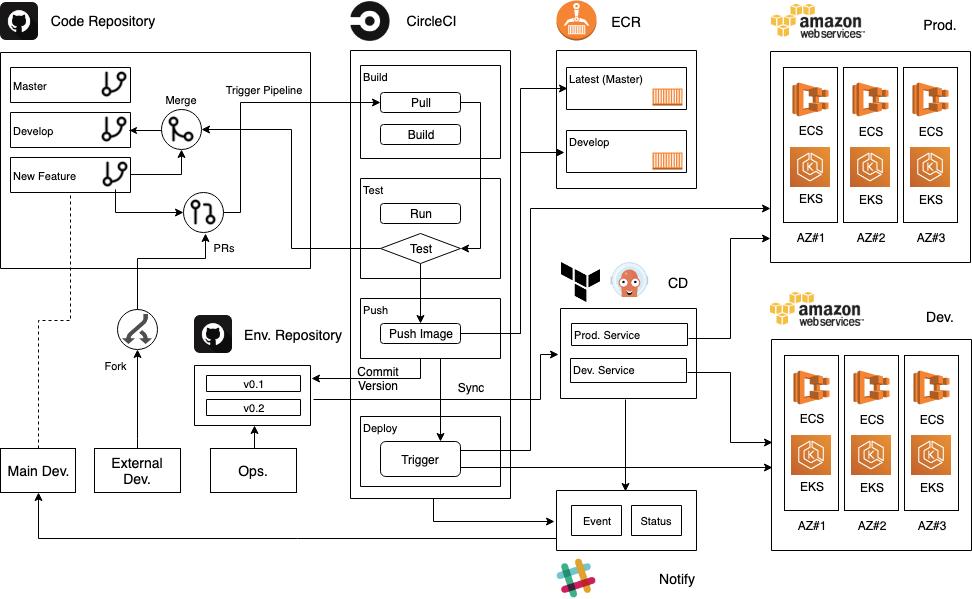
새로운 기능의 브랜치(New Feature)가 Git에 push되면 빌드와 테스트가 트리거되어 자동으로 진행되고 동시에 개발자가 PR을 작성하면 동료 및 담당 상급자에게 코드 리뷰를 받게 된다.
리뷰가 통과되고 CircleCI에서 빌드가 성공했다면 승인단계를 통해 Merge를 하고 CircleCI 가 한 번 더 빌드를 시작하고 배포까지 수행하게 된다.
ECS나 Batch로 배포는 CircleCI를 통해 직접 배포를 하고 EC2나 EKS로의 배포는 Terraform 및 ArgoCD를 통해 배포를 진행하는 방식이다.
다음번 포스팅에는 위 그림 기반으로 CircleCI와 ArgoCD를 활용하여 EKS기반 배포과정을 정리할 예정이다.