vSphere with Tanzu homelab running on ASUS PN50 (2/2)
지난글에 이어 이번에는 네트워크 구성하는 방법과 vSphere Cluster에 추가적인 Kubernetes 클러스터를 배포하는 것에 대해 이야기 하고자 한다. 이번 글도 지난글과 동일하게 virtuallyGhetto 블로그 포스팅을 참고하여 그대로 진행한 내용이라고 보면 된다.
지난 포스팅은 다음 링크에서 확인할 수 있다.
VDS(vSphere Distributed Switch) 구성
이번 구성의 경우에는 usb nic를 하나만을 사용해서 진행하기 때문에 위에서 설정했던 3개의 네트워크(Management, Frontend, Workload)로 분리하기 위해 VDS를 신규로 생성하고 기존 네트워크 어댑터를 변경하는 작업을 수행해야 한다.
먼저 신규 구성한 vCenter UI(https://vcsa.tanzu.local/ui)로 접속해 Networking 메뉴로 이동해서 VDS 메뉴 우클릭 후 Add and Manage Hosts를 선택한다.
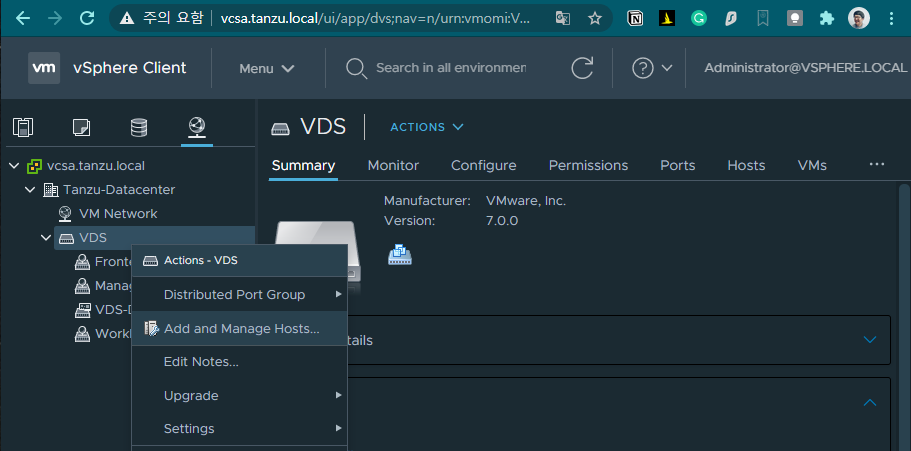
VDS 설정하는 6단계를 진행한다.
- 1단계 -
Add hosts를 선택한다. - 2단계 - ESXi host를 선택한다.
- 3단계 - pyhysical adapter를 생성한 후에 선택하게 되는데 구성한 랩에서는 USB TYPE NIC를 사용하여
vusb0어댑터를 선택하고Assign uplink에서dvUplink1를 Assign한다. - 4단계 - VMkernel adapter에서 vmk0을 선택하고
Assign port group에서 Network를 Management를 Assign한다. - 5단계 - VM Migration은 생략한다.
- 6단계 - 설정되는 내용을 확인하고 Finish를 하게 되면 기존 VCSA의 기본 네트워크가
vSwitch에서VDS로 변경되었기 때문에 VSCA Client 접속이 끊어지게 된다.
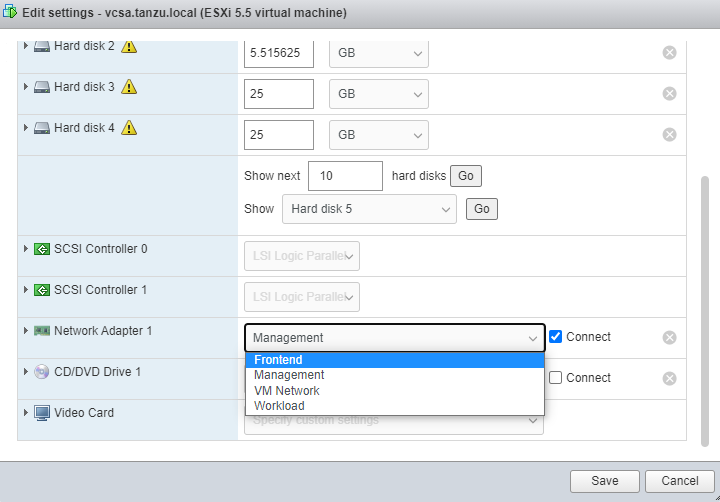
다시 ESXi Client로 접속해서 VCSA Port Group(네트워크)을 아래와 같이 기존 VM Network에서 Management로 변경하면 다시 VSCA Client로 접속이 가능하게 된다.
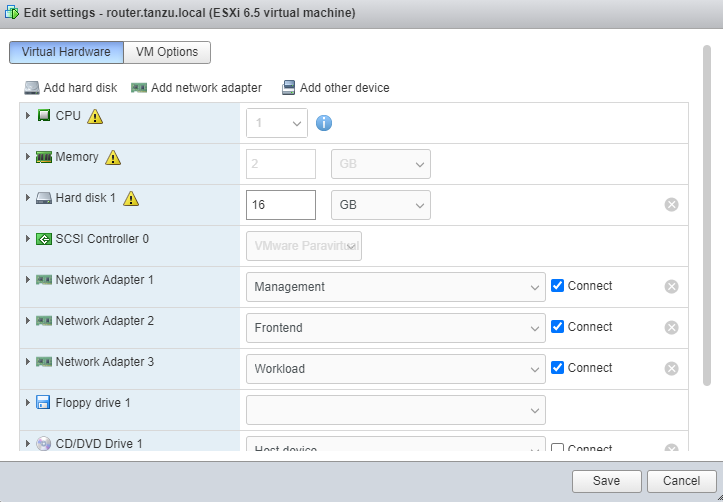
RouterVM의 Network Port Group 추가(Frontend, Workload)
이전 포스팅에서 생성한 Router VM은 구성할 내부 네트워크(10.10.0.0/24 & 10.20.0.0/24)로의 라우팅과 외부 네트워크로 NAT 및 포워딩을 위해서 필요하기 때문에 vSphere 또는 VCSA Client에서 router.tanzu.local의 네트워크 어댑터를 Frontend, Workload로 추가하는 작업이 필요하다.
구성을 완료한 후에 간단한 네트워크 구성을 보면 다음과 같다.
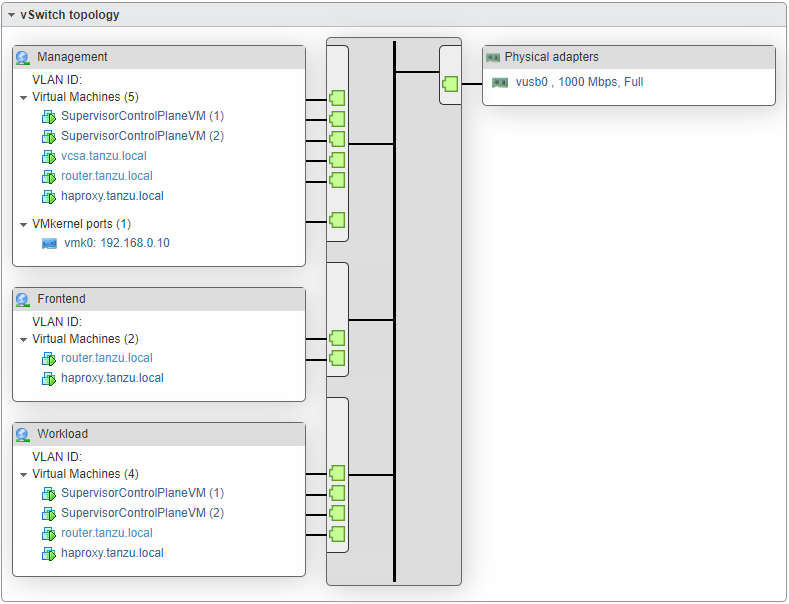
물리 인터페이스 vusb0 아래 가상 스위치가 3개 구성되어 있고 외부에서도 RouterVM을 통해 접속이 가능하도록 접속하는 로컬 머신에서 라우팅 경로 추가가 필요하다.
-
Windows
route print명령으로 인터페이스 ID를 먼저 확인하고 아래와 같이 설정한다.route ADD 10.10.0.0 MASK 255.255.255.0 192.168.0.201 METRIC 3 IF 5route ADD 10.20.0.0 MASK 255.255.255.0 192.168.0.201 METRIC 3 IF 5 -
MacOS
sudo route -n add -net 10.10.0.0/24 192.168.0.201sudo route -n add -net 10.20.0.0/24 192.168.0.201 -
WSL
sudo route -n add -net 10.10.0.0/24 gw <Gateway IP>sudo route -n add -net 10.20.0.0/24 gw <Gateway IP>
HAProxyVM 설정
이전 포스팅에서 생성한 HAProxy도 추가된 네트워크 환경으로 설정을 하기 위해 다음 스크립트를 사용한다.
구성한 환경에 맞게 스크립트내 변수들을 수정한 후 실행한다.
$HAProxyOVA = "C:\esxi\vmware-haproxy-v0.1.8.ova"
$Cluster = "Tanzu-Cluster"
$VMHost = "esxi-01.tanzu.local"
$Datastore = "datastore1"
$HAProxyDisplayName = "haproxy.tanzu.local"
$HAProxyHostname = "haproxy.tanzu.local"
$HAProxyDNS = "192.168.0.201"
$HAProxyManagementNetwork = "Management"
$HAProxyManagementIPAddress = "192.168.0.203/24" # Format is IP Address/CIDR Prefix
$HAProxyManagementGateway = "192.168.0.1"
$HAProxyFrontendNetwork = "Frontend"
$HAProxyFrontendIPAddress = "10.10.0.2/24" # Format is IP Address/CIDR Prefix
$HAProxyFrontendGateway = "10.10.0.1"
$HAProxyWorkloadNetwork = "Workload"
$HAProxyWorkloadIPAddress = "10.20.0.2/24" # Format is IP Address/CIDR Prefix
$HAProxyWorkloadGateway = "10.20.0.1"
$HAProxyLoadBalanceIPRange = "10.10.0.64/26" # Format is Network CIDR Notation
$HAProxyOSPassword = "VMware1!"
$HAProxyPort = "5556"
$HAProxyUsername = "wcp"
$HAProxyPassword = "VMware1!"
...
./deploy_3nic_haproxy.ps1
이후 HAProxy VM내에서 여러 인터페이스에서 Reverse Path Filtering을 Disable하기 위해 다음 스크립트를 실행한다.
#!/bin/bash
touch /etc/sysctl.d/999-tanzu.conf
chmod +x /etc/sysctl.d/999-tanzu.conf
IFS=$'\n'
for i in $(sysctl -a | grep rp_filter | grep 1);
do
SYSCTL_SETTING=$(echo ${i} | awk '{print $1}')
# Update live system
sysctl -w ${SYSCTL_SETTING}=0
# Persist settings upon reboot
echo "${SYSCTL_SETTING}=0" >> /etc/sysctl.d/999-tanzu.conf
done
Reverse Path Filtering는 기본적으로 하나의 인스턴스에서 여러개의 인터페이스로 들어오는 패킷의 소스IP에 대해서 라우팅 테이블을 확인한 후 패킷이 들어온 동일한 인터페이스로 다시 나가는지 확인하는 것을 말한다.rp_filter가 1로 설정이 되어있으면, 특정 인터페이스로 들어온 패킷 정보와 OS의 FIB(Forward Information Base)에 정의된 정보와 일치하지 않을경우, 들어온 패킷을 버리는 기능을 하기 때문에 위 스크립트를 통해 rp_filter 값을 모두 0으로 변경하는 것이다. 자세한 내용은 https://access.redhat.com/solutions/53031를 참고하자.
Content Library 구성
Content Library는 레포지토리의 개념으로 여러 vApp 템플릿과 ISO 이미지 등과 같은 파일들과 컨테이너 개체를 저장하고 관리할 수 있는 도구이다. 레지스트리(Registry)와 유사하지만 Content Library에는 VM templates, OVA, OVF 파일 등이 저장된다.
Menu -> Content Libraries로 이동해서 새로운 라이브러리를 추가를 한다. 이름과 vCenter Server를 선택하고 2번째 단계에서 Subscribed content library를 선택하고 Subscription URL에 https://wp-content.vmware.com/v2/latest/lib.json 를 입력하고 3번째 단계에서 저장될 데이터스토어를 선택하면 된다.
실제 위 URL은 OVF Template 여러개를 다운받는데 Tanzu Cluster내에서 Master와 Worker Node들로 쓰일 Kubernetes 1.16 ~ 1.18까지 여러개의 VM이미지 (photon OS)들이 추가가 되는것을 알 수 있다. 아래 그림을 보면 현재 Tanzu에서 사용되는 Kubernetes 클러스터 버전이 1.18.5라는 것을 알 수 있다.
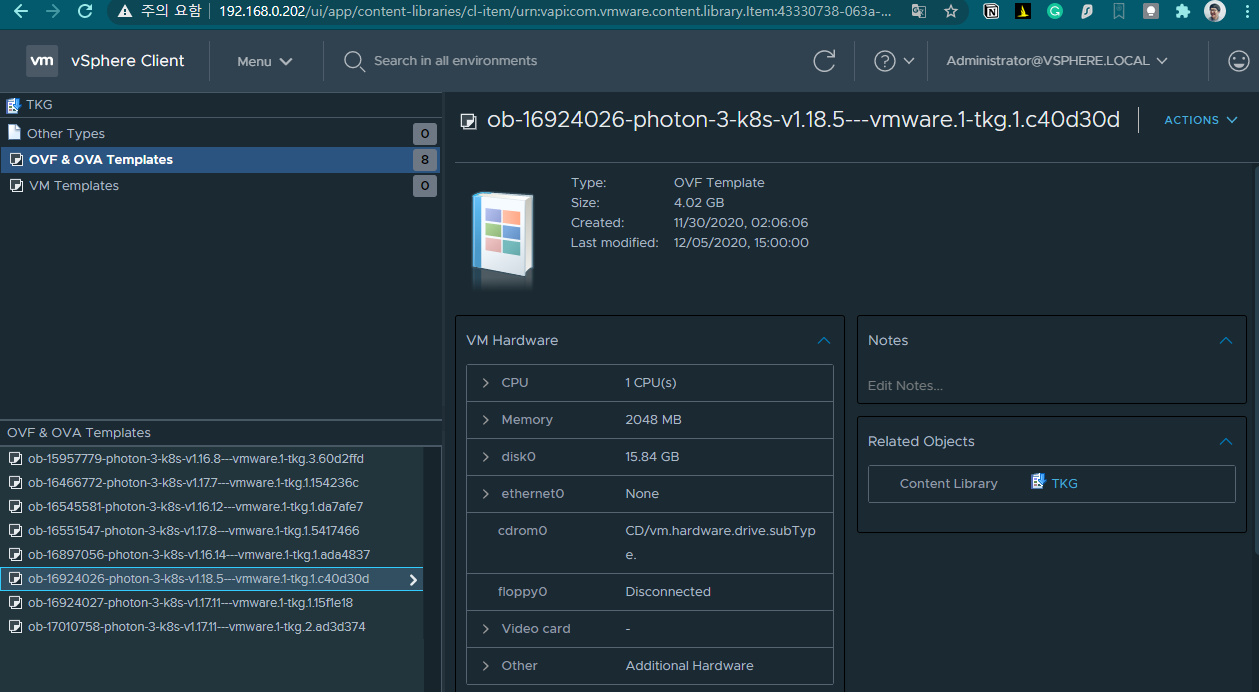
Workload Management 구성
Workload Management란 쉽게 생각하면 vSphere 기반에서 Kubernetes 클러스트를 프로비저닝하는 역할을 하는 도구라 보면 된다.
Workload Management는 다음과 같은 역할을 한다.
- Kubernetes 클러스터의 컴퓨팅, 스토리지 리소스에 대한 사이징 및 네임스페이스 관리
- Kubernetes 클러스터의 네트워크 및 DNS, NTP 및 VDS같은 네트워크 관리
- Kubernetes 클러스터 상세 정보 (Node 개수 및 상태 정보)
Workload Management에서 클러스터 생성을 스크립트로 진행하기 전에 PowerCLI를 통해 접속 테스트를 한다.
Connect-VIServer -Server vcsa.tanzu.local -User administrator@vsphere.local -Password VMware1!
Connect-CisServer -Server vcsa.tanzu.local -User administrator@vsphere.local -Password VMware1!
그리고 PowerCLI Workload Management 모듈을 설치하고 여러 환경변수들을 설정한다. 기존에 사용한 정보들과 위에서 만든 Content Library 이름으로 변경하고 실행한다.
Import-Module VMware.WorkloadManagement
$vSphereWithTanzuParams = @{
ClusterName = "Tanzu-Cluster";
TanzuvCenterServer = "vcsa.tanzu.local";
TanzuvCenterServerUsername = "administrator@vsphere.local";
TanzuvCenterServerPassword = "VMware1!";
TanzuContentLibrary = "TKG"; # Content Library 이름
ControlPlaneSize = "TINY";
MgmtNetwork = "Management";
MgmtNetworkStartIP = "192.168.0.220";
MgmtNetworkSubnet = "255.255.255.0";
MgmtNetworkGateway = "192.168.0.1";
MgmtNetworkDNS = @("192.168.0.201");
MgmtNetworkDNSDomain = "tanzu.local";
MgmtNetworkNTP = @("162.159.200.123");
WorkloadNetwork = "Workload";
WorkloadNetworkStartIP = "10.20.0.10";
WorkloadNetworkIPCount = 20;
WorkloadNetworkSubnet = "255.255.255.0";
WorkloadNetworkGateway = "10.20.0.1";
WorkloadNetworkDNS = @("192.168.0.201");
WorkloadNetworkServiceCIDR = "10.96.0.0/24";
StoragePolicyName = "Tanzu-Storage-Policy";
HAProxyVMvCenterServer = "vcsa.tanzu.local";
HAProxyVMvCenterUsername = "administrator@vsphere.local";
HAProxyVMvCenterPassword = "VMware1!";
HAProxyVMName = "haproxy.tanzu.local";
HAProxyIPAddress = "192.168.0.203";
HAProxyRootPassword = "VMware1!";
HAProxyPassword = "VMware1!";
LoadBalancerStartIP = "10.10.0.64";
LoadBalancerIPCount = 64
}
New-WorkloadManagement2 @vSphereWithTanzuParams
클러스터를 생성하는 시간은 약 40분 이상 소요되는데 Tanzu-Cluster의 Control Plane Node (Master Node) 생성이 완료되면 IP가 10.10.0.64(HAProxy Load Balancer에서 할당된 첫번째 주소)로 할당이 되는 것을 확인할 수 있다.
다음은 Namespace를 생성하는 과정을 진행한다. Workload Management에서 NEW NAMESPACE메뉴를 클릭하고 위에서 생성한 Tanzu-Cluster를 선택하고 이름(test)을 입력하고 Namespace를 생성한다.
Cluster 접속 (Kubernetes CLI)
생성된걸 확인한 후 브라우저에 해당 클러스터의 Control Plane IP (https://10.10.0.64)로 접속하면 OS별(Linux, MacOS, Windows)로 CLI 플러그인을 설치할 수 있다.
설치 및 PATH 설정을 진행하고 아래와 같이 Control Plane으로 CLI 로그인을 하면 현재 설정된 Context 확인이 가능하다.
> kubectl vsphere login --server=10.10.0.64 -u administrator@vsphere.local --insecure-skip-tls-verify
🥳vSphere with Tanzu Basic Cluster enabled by William Lam's Script 🥳
Password:
Logged in successfully.
You have access to the following contexts:
10.10.0.64
docker-desktop
nexclipper
test
If the context you wish to use is not in this list, you may need to try
logging in again later, or contact your cluster administrator.
To change context, use `kubectl config use-context <workload name>`
> kubectl config use-context nexclipper
Switched to context "nexclipper".
> kubectl get nodes
NAME STATUS ROLES AGE VERSION
422f46864113e3de3361943d14073728 Ready master 4d21h v1.18.2-6+38ac483e736488
422faddc15554b09d82907c0dfb57752 Ready master 4d21h v1.18.2-6+38ac483e736488
nexclipper namespace로 context를 전환하고 node를 확인하면 master node를 2개 확인할 수 있는데 이는 nexclipper라는 네임스페이스를 총괄하는 Super Master(Control Plane) 같은 개념이라고 볼 수 있다. 처음에 클러스터 배포전에 Namespace 리소스를 만들길래 다소 헷갈리긴 했지만 Tanzu에서의 Namespace는 기존 쿠버네티스의 리소스를 논리적으로 나누는 컨셉이 아닌, 정해진 리소스와 유저와 그룹의 권한을 먼저 Namespace로 할당하고 그담에 다시 조직이나 어플리케이션 별로 Kubernetes Workload를 다시 제공하는 컨셉이라고 보면된다.
최근에 SKT나 Kakao Enterprise 처럼 쿠버네티스 클러스터의 라이프사이클을 쿠버네티스로 관리하는 컨셉으로 이해하면 좋다. 아래 그림을 참고하면 쉽게 이해할 수 있을 것이다.

TanzuKubernetesCluster CRD를 통해 클러스터를 신규로 생성한다.
namespace: nexclipper로 설정하고 원하는 배포 버전과 이름, CNI, Control Plane, Worker Node 개수 등을 기재하게 되는데 특이한 것은 CNI는 Antrea를 사용하는것을 확인할 수 있다.
apiVersion: run.tanzu.vmware.com/v1alpha1
kind: TanzuKubernetesCluster
metadata:
name: nexclipper-cluster
namespace: nexclipper
spec:
distribution:
version: v1.17.8+vmware.1-tkg.1.5417466
settings:
network:
cni:
name: antrea
pods:
cidrBlocks:
- 193.0.2.0/16
serviceDomain: managedcluster.local
services:
cidrBlocks:
- 195.51.100.0/12
topology:
controlPlane:
class: best-effort-xsmall
count: 1
storageClass: tanzu-storage-policy
workers:
class: best-effort-xsmall
count: 1
storageClass: tanzu-storage-policy
신규 TKG 클러스터를 배포한다.
> kubectl apply -f tkc.yaml
tanzukubernetescluster.run.tanzu.vmware.com/nexclipper-cluster created
배포하고 tanzukubernetescluster 를 조회해보면 Control Plane 1개, Worker Node 1개의 v1.17.8 버전의 클러스터가 배포된것을 알 수 있다.
> kubectl get tanzukubernetescluster
NAME CONTROL PLANE WORKER DISTRIBUTION AGE PHASE
nexclipper-cluster 1 1 v1.17.8+vmware.1-tkg.1.5417466 33m running
생성한 tanzukubernetescluster로 접속하여 클러스터 정보를 확인한다.
> kubectl-vsphere login --server=10.10.0.64 -u administrator@vsphere.local --insecure-skip-tls-verify --tanzu-kubernetes-cluster-name nexclipper-cluster --tanzu-kubernetes-cluster-namespace nexclipper
> kubectl config use-context nexclipper-cluster
Switched to context "nexclipper-cluster".
> kubectl get nodes
NAME STATUS ROLES AGE VERSION
nexclipper-cluster-control-plane-95nhv Ready master 3h10m v1.17.8+vmware.1
nexclipper-cluster-workers-kp68q-78df45db5c-jzmmv Ready <none> 3h6m v1.17.8+vmware.1
생성한 클러스터에 간단한 앱을 배포한다.
Kubedoom은 Doom 게임내에서 애플리케이션(괴물)을 일부러 종료시켜 복원성을 보게하는 재미있는 앱이다.
> git clone https://github.com/storax/kubedoom.git
> cd kubedoom
> kubectl apply -f manifest/
> kubectl -n kubedoom port-forward deployment/kubedoom 5900:5900
Forwarding from 127.0.0.1:5900 -> 5900
Forwarding from [::1]:5900 -> 5900
배포한후에 포트포워딩을 한 앱으로 VNC viewer로 접속하면 재미있는 화면을 볼 수 있을 것이다. VNC 패스워드는 idbehold이다.
Tanzu 장단점 (개인의견)
하드웨서 고민, 구매, ESXi 설치, vCenter, TKG을 설치하고 아키텍처들을 찾아보면서 몇가지 장단점이 눈에 보였는데 가장 큰 장점은 하나의 네임스페이스를 만들어 Super Master(Control Plane)를 먼저 구성하고 자원(컴퓨팅, 네트워크, 스토리지 등)과 기존에 보유하고 있는 권한 체계로 할당을 한 뒤 필요할때 마다 특정 팀이나 조직에게 별도의 클러스터를 할당하는 아키텍처를 추구하고 있어 VMware 환경에서 Kubernetes를 신규 도입하고 엔터프라이즈에 적용하기 용이하다는 점이다.
또한 기본적으로 갖춰야 하는 Security Policy나 리소스 할당이 클러스터 구축이후에 되는 것이 아니라 이미 정의된 규칙으로 클러스터 구성이 이후에 진행되기 때문에 관리적인 측면에서도 장점이 있다고 볼 수 있다.
하지만 개인적으로 생각하는 단점들도 몇가지 있는데 첫번째는 용어의 중복으로 인한 혼동이 있었다는점이다. 네임스페이스나 기존 쿠버네티스에서 많이 사용되는 용어보다는 VMware에서 만든 CRD등을 미리 학습하거나 알고 있지 않으면 기존 경험이 있는 유저도 접근성이 떨어질 것 같다는 생각이 들었다.
비용 측면에서는 일단 vCenter 이외에 Workload Management 라이센스가 별도로 필요하기 때문에 자세히 알아보진 않았지만 적지 않은 비용이 들 것으로 예상된다. 게다가 많은 구성요소로 인한 자원이 소요가 있어 하나의 작은 클러스터만 띄웠음에도 64GB 머신의 메모리 사용량이 거의 60GB에 육박했기 때문에 기존 인프라 비용에 추가적인 비용에 대한 고려가 반드시 필요할 것 같다.
위에도 언급했지만 러닝커브에 대한 부분도 문제점이 될 수 있을것이다. NSX기반의 새로운 CNI뿐만 아니라 기존 VMware 운영을 하던 DevOps팀이나 인프라 운영조직의 러닝커브, 추상화 레벨이 높아져서 내가 원하는 클러스터의 이벤트나 로그를 확인할 때 탐색적으로 메뉴를 찾기가 쉽지 않은 부분들이 있었다. 그래서 트러블슈팅 때에도 로그의 원천을 찾는데 시간이 다소 걸리기도 했다.
정리
한 일주일동안 스토리지 오류로 씨름하다가 겨우 앱을 배포했지만 거의 2주동안 재미있게 구성해볼수 있었다. 솔직히 이야기하자면 개인 클러스터로 구성하는데는 추천하지 않지만 Tanzu를 공부하고 운영해야 하는 경우나 자격증을 취득하는 부분이 필요하다면 한번쯤은 해볼 가치가 있다고 생각한다.
거의 1년만에 포스팅을 작성했는데 다음 포스팅에는 Security Policy 관련한 테스트를 진행하면서 연말을 정리해볼 생각이다.