EKS Anywhere on vSphere Homelab
EKS Anywhere
EKS Anywhere는 eksctl를 사용하는 환경에서 Kubernetes Cluster API Provider vSphere 인 CAPV를 통해 vSphere 기반으로 쿠버네티스 클러스터를 구성해주는 오픈소스이다. CAPV Spec은 Kubernetes Cluster API 기반으로 쿠버네티스 스타일 API형태의 선언적(Declarative) 방식으로 쿠버네티스 클러스터의 Lifecycle을 관리하는 프로젝트이다.
Ubuntu 또는 Mac admin 환경에서 eksctl 명령어로 로컬 클러스터들을 관리하고 클러스터를 생성, 삭제할 수 있다. 일단 기본적으로 클러스터를 생성하고 관리하는 방식이 eksctl과 거의 ��유사하다. 또한 EKS 서비스의 배포 버전과 동일한 버전을 사용함으로써 (포스팅 당시 버전 1.21) vSphere 기반 하이브리드 환경에서의 쿠버네티스 클러스터 및 워크로드 관리를 편하게 할 수 있다.
크게 EKS native 서비스와 크게 다른점 몇가지는 다음과 같다.
- 컴퓨팅 환경 : vSphere, Docker(개발환경 구성시)
- 노드 지원 OS : BottleRocket, Ubuntu
- CNI : Cilium
자세한 내용은 비교표를 참고하자.
사전 준비사항
로컬 관리 환경
- Docker 20.x 이상 버전
- Mac OS(10.15) / Ubuntu(20.04.2 LTS)
- CPU 4코어
- 메모리 16GB
- 디스크 30GB
vSphere
https://anywhere.eks.amazonaws.com/docs/reference/vsphere/vsphere-prereq/
- vCenter 환경의 vSphere 7.0 이상
- 최소 VM 4대 (각 2 vCPU, 8GB 메모리, 25GB 디스크 이상 권장)
- Control Plane 1대
- etcd 노드 1대
- worker 노드 2대
- DHCP 환경
- API 서버 용 Static IP 1개
- 외부 바이너리, 이미지 다운로드를 위한 네트워크 환경
- 클러스터 자체에서 방화벽 등으로 인한 인터넷이 안되는 경우 프록시 구성을 통해 가능함
Homelab 구성환경
기존에 운영하던 ESXi 환경을 그대로 활용하도록 했다. 추가적으로 하드웨어를 구비하기 위해 비용이 발생한부분은 없다.
Hardware
- Dell Precision Tower 3620
- Intel(R) Xeon(R) CPU E3-1240L v5
- TeamGroup DDR4-2666 16GB * 4ea
- (VM 용) SAMSUNG NVMe SSD PM981 - 1TB
- (ESXi 용) Sandisk SSD Z410- 240GB
Software
- vSphere 7.0 Update 3
- vCenter 7.0.3 (VSCA)
- Docker Desktop 4.2.0버전을 사용
- 4.3.0 버전 하위 호환 문제가있어 금번 테스트 환경에서는 4.2.0 사용
- 도커 리소스를 최소
8vCPU,16GB로 설정
- kubectl v1.23.4
- eksctl v0.85.0
- eksctl-anywhere v0.7.0
- aws-iam-authenticator v0.5.5
- bottlerocket OVA v1.21 (자동 생성되는 OVA로 별도 구성이 필요없다)
클러스터 환경구성
공식 홈페이지의 클러스터 생성, 삭제 워크플로우를 참고하여 사전 구성된 Homelab에 적용한다.
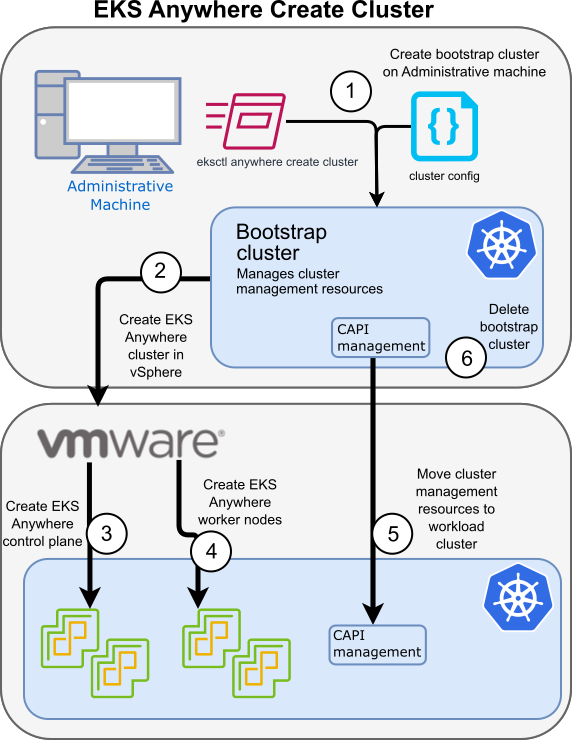
처음에는 eksctl 명령으로 클러스터를 생성하는 과정으로 사전에 생성한 cluster config yaml을 통해 로컬 도커 엔진에 bootstrap을 하는 명령을 내린다. 이때 로컬 도커 엔진에서는 Docker in Docker 엔진인 kind를 통해 클러스터 번들 컨피그를 생성한다.
clusterctl를 통해 Cluster API Provider Docker형태로 부모(bootstrap) 클러스터를 만드는 과정이 eksctl anywhere 명령으로 추상화 되는것이라 볼 수 있다.
해당 단계에서 먼저 Bastion Host나 관리 머신에 kubectl, eksctl, eksctl-anywhere, aws-iam-authenticator 등이 설치되어 있는지 확인한다.
https://anywhere.eks.amazonaws.com/docs/getting-started/install/
homelab 이름으로 클러스터 컨피그를 생성한다.
CLUSTER_NAME=homelab
eksctl anywhere generate clusterconfig $CLUSTER_NAME \
--provider vsphere > $CLUSTER_NAME.yaml
모든 컨피그에 대한 상세 설정은 vSphere configuration 에�서 확인할 수 있다.
생성된 컨피그를 하나씩 살펴보자.
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: homelab
namespace: default
spec:
clusterNetwork:
cni: cilium
pods:
cidrBlocks:
- 192.168.0.0/20
services:
cidrBlocks:
- 10.96.0.0/12
controlPlaneConfiguration:
count: 2
endpoint:
host: 192.168.31.3
machineGroupRef:
kind: VSphereMachineConfig
name: homelab-cp
datacenterRef:
kind: VSphereDatacenterConfig
name: homelab
externalEtcdConfiguration:
count: 1
machineGroupRef:
kind: VSphereMachineConfig
name: homelab-etcd
gitOpsRef:
kind: GitOpsConfig
name: cluster-gitops
kubernetesVersion: "1.21"
managementCluster:
name: homelab
workerNodeGroupConfigurations:
- count: 2
machineGroupRef:
kind: VSphereMachineConfig
name: homelab
name: md-0
첫번째는 Cluster 리소스로 Cluster의 이름과 클러스터 전반 설정과 Control Plane, Data Plane, etcd VM의 버전, 개수 등을 정할 수 있다.
클러스터 이름은 homelab으��로 설정한다. 기본적으로 CNI는 Cilium을 사용하는 구조이기 때문에 필수적으로 cilium로 설정해야 한다. 그리고 kubeadm 구성시 필요한 pods.cidrBlocks과 services.cidrBlocks에서 파드와 서비스가 사용할 네트워크 대역을 설정한다. 둘다 CNI에서 통신되는 가상 네트워크 대역이기 때문에 현재 사용중인 샤오미 공유기 대역(192.168.31.x)과 충돌하지 않으면서 라우팅에 문제되지 않고 현재 네트워크에 사용되지 않는 대역(192.168.0.0/20, 10.96.0.0/12) 으로 설정했다.
DHCP 유의사항: 본인의 경우 Xiaomi 공유기를 사용중인데 별도의 DHCP서버를 구성하지 않고 사용을 하고 있어서인지, 신규 노드를 위한 VM이 생성되고
bottlerocketOS가 기동될때 호스트명이MiWifi-R3600-SRV이런식으로 대소문자를 포함한 형태로 자동 생성되다 보니 부팅이 되지 않는 현상이 발생했다. 이에 별도의 DHCP 구성을 통해 진행을 하면 해당 이슈를 피할수 있다.
controlPlaneConfiguration 필드에서는 controlPlane 노드의 count와 endpoint를 설정해야 한다. count 초기 값은 2로 되어 있지만 홈랩의 자원이 부족하기 때문에 1로 설정했다. 실제 프로덕션에서는 2이상을 권고한다. 그리고 endpoint.host는 쿠버네티스 API서버 엔드포인트로 실제 kubectl 명령 및 사용자와 인터페이스를 위한 접근 가능한 DHCP 할당으로 충돌되지 않는 네트워크 대역의 고정 IP로 설정한다. machineGroupRef는 이후 생성할 VM spec에 매칭시킬 label 값으로 자동 생성된다.
externalEtcdConfiguration는 etcd 구성을 위한 필드로 count는 기본설정 값이 3이지만 홈랩 환경에서는 1로 구성하였다. 실제 프로덕션에서는 Raft 알고리즘 기반 Redundancy 구성을 위해 3이상을 권고한다.
gitOpsRef는 GitOps 형태로 클러스터를 관리하기 위해 참조하는 값으로 아래 GitOpsConfig 에서 사용할 이름 cluster-gitops 를 명시한다.
kubernetesVersion은 EKS 배포 버전와 동일한 1.21로 설정한다.
workerNodeGroupConfigurations은 워커노드 구성으로 count를 2로 설정하였다.
다음은 배포되는 vSphere spec을 정의하는 리소스로 VSphereDatacenterConfig이다.
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: VSphereDatacenterConfig
metadata:
name: homelab
spec:
datacenter: "Datacenter"
insecure: false
network: "VM Network"
server: "192.168.31.2"
thumbprint: "**:89:91:5B:02:50:F6:41:D0:DE:6B:A0:B8:43:41:A4:81:03:**"
spec에서는 실제 vCenter의 엔드포인트, datacenter, network 정보 등을 입력한다.
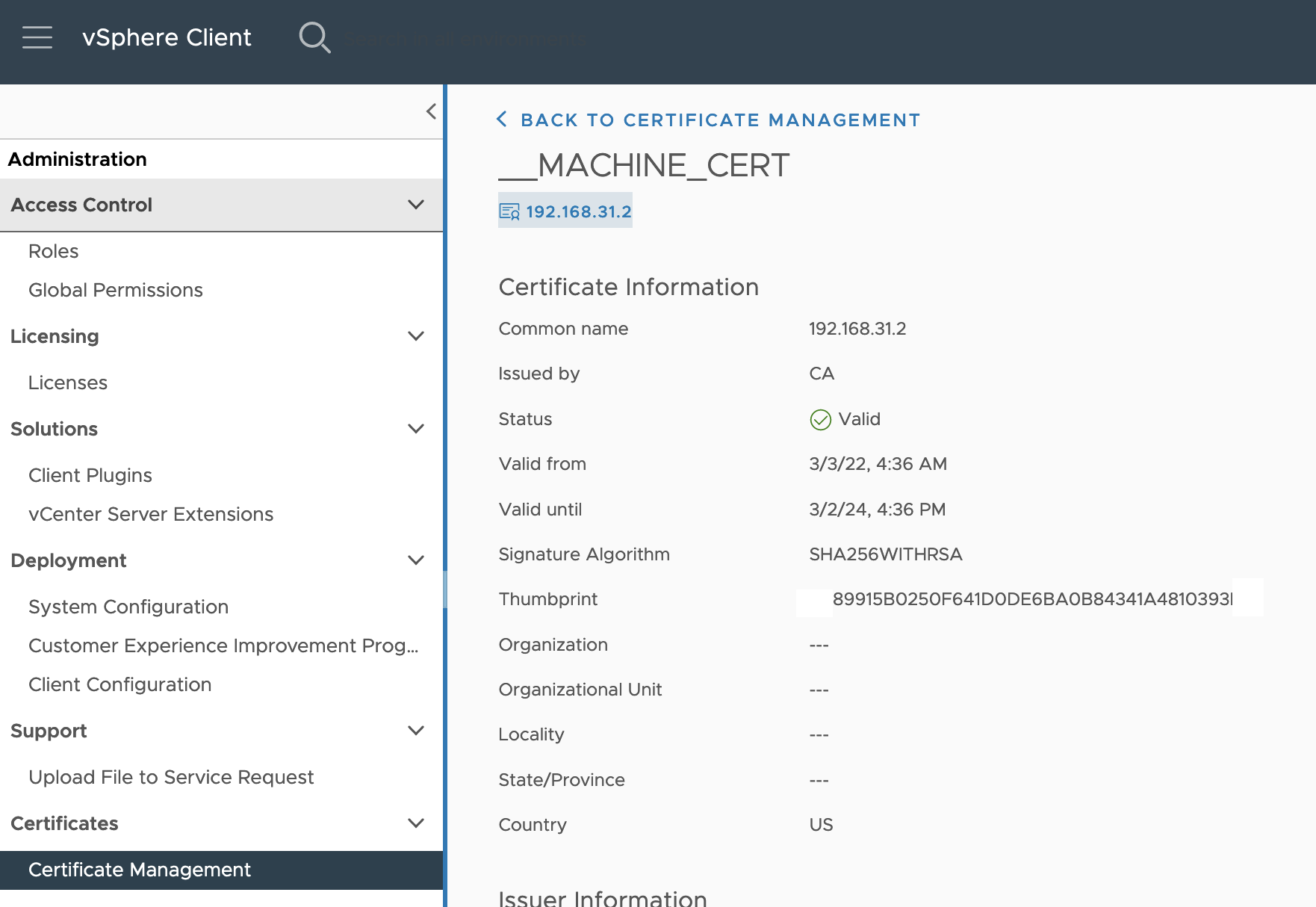
유의사항 :
insecure옵션의 경우 기본값이 false로 되어 있다. 해당 값이false의 경우 아래 그림에 있는 것 처럼 보통 vCenter 메뉴에서thumbprint값을 확인할 수 있고 해당 값을**:89:91:5B:02:50:F6:41:D0:DE:6B:A0:B8:43:41:A4:81:03:**형태로 변경하여 사용하거나 govc를 사용하여govc about.cert -thumbprint -k명령어로 확인이 가능하다.
마지막은 각 노드 역할(control plane, etcd, worker)별로 사용할 OS 및 리소스 spec을 정의하는 컨피그이다. 위 Cluster 리소스에서 설정된 machineGroupRef.name으로 매칭되는 값을 metadata로 자동 생성 해주고 모두 유사하기 때문에 이중 VSphereMachineConfig만 살펴본다.
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: VSphereMachineConfig
metadata:
name: homelab-cp
spec:
datastore: "datastore2"
diskGiB: 25
folder: "cp"
memoryMiB: 8192
numCPUs: 2
osFamily: bottlerocket
resourcePool: "*/Resources"
users:
- name: ec2-user
sshAuthorizedKeys:
- ssh-rsa AAAAB3******U= vsphere
Datacenter에 구성한 datastore중 설치되는 VM 영역이 사용할 대상 datastore를 입력한다. VM디스크 diskGiB, Datacenter folder, VM메모리 memoryMiB, vCPU numCPUs를 입력하고, resourcePool은 지정 리소스 그룹을 별도로 설정하지 않았기 때문에 "*/Resources"로 설정한다. 그리고 osFamily는 ubuntu, bottlerocket두가지로 제공이 되는데 기본값은 bottlerocket이고, 해당 이미지의 기본 user는 ec2-user로 설정하고 해당 VM에 SSH접근을 위해서 별도로 생성한 sshAuthorizedKeys를 입력한다.
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: GitOpsConfig
metadata:
name: cluster-gitops
namespace: default
spec:
flux:
github:
branch: main
clusterConfigPath: clusters/homelab
fluxSystemNamespace: flux-system
owner: ddiiwoong
personal: true
repository: eks-anywhere-homelab
마지막은 클러스터를 GitOps 스타일로 관리하기 위해 GitOpsConfig를 추가한다. spec 에서 사용할 github의 branch, github 레포 아래 컨피그가 저장될 경로인 clusterConfigPath, gitops 오픈소스인 Flux가 구성될 네임스페이스인 fluxSystemNamespace, github account인 owner, repo 이름이 되는 repository 까지 설정한다. 해당 구성을 포함한 채로 클러스터를 배포하게 되면 클러스터가 생성되는 중에 선언한 repository로 이후 관리될 클러스터 컨피그 및 kustomize 파일 등을 commit하게 된다.
클러스터 생성
나머지 etcd, worker node 도 VSphereMachineConfig를 동일한 형식으로 작성하고, vSphere 관련 인증정보와 gitops로 활용할 레포의 github token을 환경변수로 입력하여 클러스터 생성을 진행한다. 홈랩으로 구성한 샘플 컨피그는 링크에서 확인할 수 있다.
> export EKSA_VSPHERE_USERNAME='administrator@ddii.local'
> export EKSA_VSPHERE_PASSWORD='***********'
> export EKSA_GITHUB_TOKEN=ghp_************************
> eksctl anywhere create cluster -f homelab.yaml
Warning: The recommended size of an external etcd cluster is 3 or 5
Checking Github Access Token permissions
✅ Github personal access token has the required repo permissions
Performing setup and validations
✅ Connected to server
✅ Authenticated to vSphere
✅ Datacenter validated
✅ Network validated
✅ Datastore validated
✅ Folder validated
✅ Resource pool validated
✅ Datastore validated
✅ Folder validated
✅ Resource pool validated
✅ Datastore validated
✅ Folder validated
✅ Resource pool validated
✅ Control plane and Workload templates validated
✅ Vsphere Provider setup is valid
✅ Flux path
✅ Create preflight validations pass
Creating new bootstrap cluster
Installing cluster-api providers on bootstrap cluster
Provider specific setup
Creating new workload cluster
Installing networking on workload cluster
Installing storage class on workload cluster
Installing cluster-api providers on workload cluster
Installing EKS-A secrets on workload cluster
Moving cluster management from bootstrap to workload cluster
Installing EKS-A custom components (CRD and controller) on workload cluster
Creating EKS-A CRDs instances on workload cluster
Installing AddonManager and GitOps Toolkit on workload cluster
Adding cluster configuration files to Git
Enumerating objects: 20, done.
Counting objects: 100% (20/20), done.
Compressing objects: 100% (12/12), done.
Total 20 (delta 1), reused 19 (delta 0), pack-reused 0
Finalized commit and committed to local repository {"hash": "ea4293c849725e593704c2a8ff71a708ad8cf8f2"}
Writing cluster config file
Deleting bootstrap cluster
🎉 Cluster created!
각 단계를 순서대로 간단히 살펴보면 처음 bootstrap cluster 구성 단계에서는 아래와 같은 일을 수행한다.
- Github Access Token 권한 확인
- vSphere 인증
- vSphere 리소스(Datacenter, Network, Datastore, Folder 등) 검증
- Control Plane, Workload Plane 템플릿 검증
- kind로 bootstrap cluster 생성
- cluster-api provider 역할을 하는 CAPI(Cluster API) 설치
다음은 생성된 bootstrap cluster의 CAPI 관리도구가 vSphere 클러스터에 연결후에 진행한다.
- govc를 사용해서 연결된 vSphere 클러스터에 새로운 etcd를 포함한 Control, Workload 노드 생성
- Cilium CNI 추가
- Storage Class 추가
- 구성된 Workload Cluster에 CAPI 추가
- provider 셋업
- 추가적인 CRD 및 GitOps 컴포넌트 추가
- GitOps를 위해 최초 생성된 cluster config를 지정한 repo에 Commit
- 마지막으로 로컬 관리 머신에 cluster config를 저장
각각의 단계에 대한 설명은 다음 링크에서 확인할 수 있다.
처음 몇번 시도를 하다보면 여러가지 에러사항을 만나게 된다. 해당 단계의 디버그 레벨 출력을 보기 위해서는 -v 9 플래그를 추가해서 설치를 진행하면 상세 내역을 확인할 수 있는데 debug 레벨로 마지막 몇줄 로그를 살펴보면 도커에서 kind로 �도커내에 클러스터를 구성한 이후에 docker내 kind 클러스터를 삭제하는 것을 확인할 수 있다.
2022-03-04T15:23:33.638+0900 V4 Deleting kind cluster {"name": "homelab-eks-a-cluster"}
2022-03-04T15:23:33.638+0900 V6 Executing command {"cmd": "/usr/local/bin/docker exec -i eksa_1646374542969789000 kind delete cluster --name homelab-eks-a-cluster"}
Deleting cluster "homelab-eks-a-cluster" ...
2022-03-04T15:23:36.244+0900 V0 🎉 Cluster upgraded!
2022-03-04T15:23:36.244+0900 V4 Task finished {"task_name": "delete-kind-cluster", "duration": "4.560798797s"}
2022-03-04T15:23:36.244+0900 V4 ----------------------------------
2022-03-04T15:23:36.244+0900 V4 Tasks completed {"duration": "7m50.030420843s"}
2022-03-04T15:23:37.227+0900 V3 Cleaning up long running container {"name": "eksa_1646374542969789000"}
2022-03-04T15:23:37.228+0900 V6 Executing command {"cmd": "/usr/local/bin/docker rm -f -v eksa_1646374542969789000"}
몇가지 경험한 에러 사항을 나열해 보면 위에서도 언급한 내용과 같이 Cluster 컨피그 내 vSphere thumbprint를 반드시 넣어주는것이 좋다. 공식 가이드에는 insecure 필드를 true로 설정하고 thumbprint를 null로 진행할 경우 아래와 같이 kubeconfg secret을 구성단계에서 실패하거나 Workload 노드가 join할 때 에러가 발생하게 된다.
$ eksctl anywhere create cluster -f eksa-mgmt-cluster.yaml
...
collecting management cluster diagnostics
⏳ Collecting support bundle from cluster, this can take a while {"cluster": "bootstrap-cluster", "bundle": "mgmt/generated/bootstrap-cluster-2022-03-02T23:25:32+09:00-bundle.yaml", "since": 1646227532274217000, "kubeconfig": "mgmt/generated/mgmt.kind.kubeconfig"}
Support bundle archive created {"path": "support-bundle-2022-03-02T14_25_34.tar.gz"}
Analyzing support bundle {"bundle": "mgmt/generated/bootstrap-cluster-2022-03-02T23:25:32+09:00-bundle.yaml", "archive": "support-bundle-2022-03-02T14_25_34.tar.gz"}
Analysis output generated {"path": "mgmt/generated/bootstrap-cluster-2022-03-02T23:27:23+09:00-analysis.yaml"}
collecting workload cluster diagnostics
Error: failed to create cluster: error checking availability of kubeconfig secret: kubeconfig secret does not exist
정상적으로 클러스터 배포가 되었으면 eksctl config yaml이 포함된 디렉토리 하위에 클러스터 이름으로 새로운 디렉토리와 kubeconfig와 실제 배포된 cluster config를 확인 할 수 있다.
> tree
.
├── homelab
│ ├── homelab-eks-a-cluster.kubeconfig
│ └── homelab-eks-a-cluster.yaml
├── homelab.yaml
기존 kubeconfig와 merge를 위해 krew를 통해 설치한 konfig 도구를 사용해서 기존 컨피그와 병합한다.
> kubectl konfig merge ~/.kube/config ./homelab/homelab-eks-a-cluster.kubeconfig > merged-and-flattened-config
> mv merged-and-flattened-config ~/.kube/config
생성된 리소스를 확인해보면 Bottlerocket OS 이미지와 containerd://1.5.8+bottlerocket CRI를 확인할 수 있다. 노드 이름이 IP로 보이는 이유는 DHCP서버를 별도로 두지 않아 Prefix 할당이 되지 않는 가정용 공유기 환경에서 발생하는 현상이다.
> kubectl get node -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
192.168.31.186 Ready control-plane,master 9m v1.21.6 192.168.31.186 192.168.31.186 Bottlerocket OS 1.5.3 (vmware-k8s-1.21) 5.10.93 containerd://1.5.8+bottlerocket
192.168.31.187 Ready <none> 8m v1.21.6 192.168.31.187 192.168.31.187 Bottlerocket OS 1.5.3 (vmware-k8s-1.21) 5.10.93 containerd://1.5.8+bottlerocket
192.168.31.188 Ready <none> 7m v1.21.6 192.168.31.188 192.168.31.188 Bottlerocket OS 1.5.3 (vmware-k8s-1.21) 5.10.93 containerd://1.5.8+bottlerocket
192.168.31.189 Ready control-plane,master 7m v1.21.6 192.168.31.189 192.168.31.189 Bottlerocket OS 1.5.3 (vmware-k8s-1.21) 5.10.93 containerd://1.5.8+bottlerocket
CRD 리스트를 확인해보자. 많은 CRD중에 x-k8s.io로 필터를 하면 machine, vsphere, cluster 관련된 정보를 확인할수 있다.
> kubectl get crd | grep "x-k8s.io"
clusterclasses.cluster.x-k8s.io 2022-03-04T14:30:28Z
clusterresourcesetbindings.addons.cluster.x-k8s.io 2022-03-04T14:30:28Z
clusterresourcesets.addons.cluster.x-k8s.io 2022-03-04T14:30:28Z
clusters.cluster.x-k8s.io 2022-03-04T14:30:28Z
etcdadmclusters.etcdcluster.cluster.x-k8s.io 2022-03-04T14:30:41Z
etcdadmconfigs.bootstrap.cluster.x-k8s.io 2022-03-04T14:30:38Z
kubeadmconfigs.bootstrap.cluster.x-k8s.io 2022-03-04T14:30:34Z
kubeadmconfigtemplates.bootstrap.cluster.x-k8s.io 2022-03-04T14:30:34Z
kubeadmcontrolplanes.controlplane.cluster.x-k8s.io 2022-03-04T14:30:45Z
kubeadmcontrolplanetemplates.controlplane.cluster.x-k8s.io 2022-03-04T14:30:47Z
machinedeployments.cluster.x-k8s.io 2022-03-04T14:30:29Z
machinehealthchecks.cluster.x-k8s.io 2022-03-04T14:30:29Z
machinepools.cluster.x-k8s.io 2022-03-04T14:30:30Z
machines.cluster.x-k8s.io 2022-03-04T14:30:30Z
machinesets.cluster.x-k8s.io 2022-03-04T14:30:30Z
providers.clusterctl.cluster.x-k8s.io 2022-03-04T14:27:56Z
vsphereclusteridentities.infrastructure.cluster.x-k8s.io 2022-03-04T14:30:51Z
vsphereclusters.infrastructure.cluster.x-k8s.io 2022-03-04T14:30:52Z
vsphereclustertemplates.infrastructure.cluster.x-k8s.io 2022-03-04T14:30:52Z
vspheredeploymentzones.infrastructure.cluster.x-k8s.io 2022-03-04T14:30:52Z
vspherefailuredomains.infrastructure.cluster.x-k8s.io 2022-03-04T14:30:53Z
vspheremachines.infrastructure.cluster.x-k8s.io 2022-03-04T14:30:53Z
vspheremachinetemplates.infrastructure.cluster.x-k8s.io 2022-03-04T14:30:53Z
vspherevms.infrastructure.cluster.x-k8s.io 2022-03-04T14:30:54Z
이중 machine CRD를 확인해보면 etcd를 볼 수 있는데 이는 VM인스턴스 형태의 외부 리소스 형태로 배포되기 때문에 쿠버네티스 노드 정보에서는 확인할수 없던 etcd 머신을 확인을 할 수 있다.
> kubectl get machine -A
NAMESPACE NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION
eksa-system homelab-etcd-jrhvt homelab vsphere://421b44b1-6017-8469-734b-01bcf68cb459 Running 11m
eksa-system homelab-j5mql homelab 192.168.31.186 vsphere://421b4382-0727-3afc-5c47-b73455010d35 Running 11m v1.21.5-eks-1-21-8
eksa-system homelab-md-0-76478bb486-jszj4 homelab 192.168.31.187 vsphere://421b4dc9-b7c6-f0a2-0b50-e5379748b9a9 Running 11m v1.21.5-eks-1-21-8
eksa-system homelab-md-0-76478bb486-rpxlm homelab 192.168.31.188 vsphere://421b20a4-9870-cd20-4cff-67bb4a9d8372 Running 11m v1.21.5-eks-1-21-8
eksa-system homelab-w6bq8 homelab 192.168.31.189 vsphere://421befe9-e26a-3f18-9ccf-3fe32dd57fd2 Running 11m v1.21.5-eks-1-21-8
초기 구성 파드들을 살펴보면 CAPI 관련 리소스, cert-manager, eks-anywhere, Cilium CNI, vSphere 관련 컨트롤러 등을 확인할 수 있다.
> kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
capi-kubeadm-bootstrap-system capi-kubeadm-bootstrap-controller-manager-694cc79bb7-2h29c 1/1 Running 0 3h42m
capi-kubeadm-control-plane-system capi-kubeadm-control-plane-controller-manager-5b6b48dd8c-g6md4 1/1 Running 0 3h42m
capi-system capi-controller-manager-689cd9b4fd-vxpc8 1/1 Running 0 3h42m
capv-system capv-controller-manager-6b467446b9-n865b 1/1 Running 0 3h42m
cert-manager cert-manager-7988d4fb6c-72fw7 1/1 Running 0 3h44m
cert-manager cert-manager-cainjector-6bc8dcdb64-7d7qg 1/1 Running 0 3h44m
cert-manager cert-manager-webhook-68979bfb95-hjq8m 1/1 Running 0 3h44m
eksa-system eksa-controller-manager-5c74596687-45v8t 2/2 Running 0 3h41m
etcdadm-bootstrap-provider-system etcdadm-bootstrap-provider-controller-manager-74c86ffb56-cpw9k 1/1 Running 0 3h42m
etcdadm-controller-system etcdadm-controller-controller-manager-7894945688-js7z4 1/1 Running 0 3h42m
kube-system cilium-bq5gq 1/1 Running 0 3h44m
kube-system cilium-fn2f7 1/1 Running 0 3h44m
kube-system cilium-lgptt 1/1 Running 0 3h44m
kube-system cilium-operator-86d59d5c88-76z2t 1/1 Running 1 3h44m
kube-system cilium-operator-86d59d5c88-9p4s9 1/1 Running 0 3h44m
kube-system cilium-w55nc 1/1 Running 0 68m
kube-system cilium-wk89j 1/1 Running 0 68m
kube-system coredns-745c7986c7-k729b 1/1 Running 0 3h46m
kube-system coredns-745c7986c7-thtbm 1/1 Running 0 3h46m
kube-system kube-apiserver-192.168.31.189 1/1 Running 0 3h46m
kube-system kube-controller-manager-192.168.31.189 1/1 Running 0 3h46m
kube-system kube-proxy-6xcdk 1/1 Running 0 3h44m
kube-system kube-proxy-d4qbv 1/1 Running 0 68m
kube-system kube-proxy-mhzb4 1/1 Running 0 3h46m
kube-system kube-proxy-vrw2p 1/1 Running 0 68m
kube-system kube-proxy-xkfmh 1/1 Running 0 3h44m
kube-system kube-scheduler-192.168.31.189 1/1 Running 0 3h46m
kube-system kube-vip-192.168.31.189 1/1 Running 0 3h46m
kube-system vsphere-cloud-controller-manager-bxp4t 1/1 Running 2 68m
kube-system vsphere-cloud-controller-manager-jdncv 1/1 Running 3 3h44m
kube-system vsphere-cloud-controller-manager-jhbbp 1/1 Running 2 3h44m
kube-system vsphere-cloud-controller-manager-jpn89 1/1 Running 2 68m
kube-system vsphere-cloud-controller-manager-qblld 1/1 Running 1 3h46m
kube-system vsphere-csi-controller-576c9c8dc8-9k2lm 5/5 Running 0 3h46m
kube-system vsphere-csi-node-9fbs2 3/3 Running 0 68m
kube-system vsphere-csi-node-ffjlv 3/3 Running 0 3h44m
kube-system vsphere-csi-node-lrkqk 3/3 Running 0 68m
kube-system vsphere-csi-node-s49x6 3/3 Running 0 3h46m
kube-system vsphere-csi-node-z5hdz 3/3 Running 0 3h44m
로드밸런서 구성
쿠버네티스 v1.14.2 이후 버전부터는 IPVS모드에서 kube-proxy 사용을 위해 MetalLB 구성전에 strict ARP 모드를 활성화해야한다.
> kubectl get configmap kube-proxy -n kube-system -o yaml | \
sed -e "s/strictARP: false/strictARP: true/" | \
kubectl apply -f - -n kube-system
> kubectl describe configmap -n kube-system kube-proxy | grep ARP
strictARP: true
미리 서비스에서 사용할 IP 대역을 지정하기 위해 helm chart configmap value를 미리 생성한다.
cat << 'EOF' >> values.yaml
configInline:
address-pools:
- name: default
protocol: layer2
addresses:
- 192.168.31.10-192.168.31.19
EOF
metallb가 사용할 네임스페이스 metallb-system를 만들고 위 configmap value파일로 metalLB를 설치한다.
> helm repo add metallb https://metallb.github.io/metallb
> kubectl create ns metallb-system
> helm install metallb metallb/metallb -n metallb-system -f values.yaml
> kubectl get all -n metallb-system
NAME READY STATUS RESTARTS AGE
pod/metallb-controller-69bbb4669c-2pdnk 1/1 Running 0 115s
pod/metallb-speaker-2km46 1/1 Running 0 115s
pod/metallb-speaker-cm9xw 1/1 Running 0 115s
pod/metallb-speaker-dptbx 1/1 Running 0 115s
pod/metallb-speaker-jk7hn 1/1 Running 0 115s
pod/metallb-speaker-kgfkl 1/1 Running 0 115s
pod/metallb-speaker-t7qkw 1/1 Running 0 115s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/metallb-speaker 6 6 6 6 6 kubernetes.io/os=linux 115s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/metallb-controller 1/1 1 1 115s
NAME DESIRED CURRENT READY AGE
replicaset.apps/metallb-controller-69bbb4669c 1 1 1 115s
metallb 리소스가 모두 정상으로 올라오면 서비스 하나를 LoadBalancer 타입으로 배포하고 해당 서비스로 접속해본다.
> kubectl apply -f https://anywhere.eks.amazonaws.com/manifests/hello-eks-a.yaml
> kubectl expose deployment hello-eks-a --port=80 --type=LoadBalancer --name=hello-eks-a-lb
> SVC1EXIP=$(kubectl get svc hello-eks-a-lb -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
> curl $SVC1EXIP
⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢
Thank you for using
███████╗██╗ ██╗███████╗
██╔════╝██║ ██╔╝██╔════╝
█████╗ █████╔╝ ███████╗
██╔══╝ ██╔═██╗ ╚════██║
███████╗██║ ██╗███████║
╚══════╝╚═╝ ╚═╝╚══════╝
█████╗ ███╗ ██╗██╗ ██╗██╗ ██╗██╗ ██╗███████╗██████╗ ███████╗
██╔══██╗████╗ ██║╚██╗ ██╔╝██║ ██║██║ ██║██╔════╝██╔══██╗██╔════╝
███████║██╔██╗ ██║ ╚████╔╝ ██║ █╗ ██║███████║█████╗ ██████╔╝█████╗
██╔══██║██║╚██╗██║ ╚██╔╝ ██║███╗██║██╔══██║██╔══╝ ██╔══██╗██╔══╝
██║ ██║██║ ╚████║ ██║ ╚███╔███╔╝██║ ██║███████╗██║ ██║███████╗
╚═╝ ╚═╝╚═╝ ╚═══╝ ╚═╝ ╚══╝╚══╝ ╚═╝ ╚═╝╚══════╝╚═╝ ╚═╝╚══════╝
You have successfully deployed the hello-eks-a pod hello-eks-a-9644dd8dc-647bq
For more information check out
https://anywhere.eks.amazonaws.com
⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢
인그레스 컨트롤러 설치
API Gateway 오픈소스인 Gloo Edge를 인그레스 컨트롤러로 사용할 수 있다. Envoy 기반의 경량화된 오픈소스로 쿠버네티스 네이티브한 옵션들을 제공하기 때문에 개인적으로 선호하는편이다. 공식 설치 문서는 다음 링크에서 확인할 수 있다.
https://docs.solo.io/gloo-edge/latest/installation/ingress/
공식 CLI인 glooctl나 Helm Chart로 설치를 진행할 수 있다. ingress를 구성하기 위해 gateway.enabled value값을 false로 ingress.enabled value를 true로 변경하여 inline 구성으로 배포를 진행한다.
helm repo add gloo https://storage.googleapis.com/solo-public-helm
helm repo update
kubectl create namespace gloo-system
helm install gloo gloo/gloo --namespace gloo-system \
--set gateway.enabled=false,ingress.enabled=true
> kubectl get all -n gloo-system
NAME READY STATUS RESTARTS AGE
pod/discovery-9694c78f6-zrf4l 1/1 Running 0 88s
pod/gloo-7cd566cb69-bfghh 1/1 Running 0 88s
pod/ingress-7fb5c9687d-qq98j 1/1 Running 0 88s
pod/ingress-proxy-5cc555c45b-9mj9n 1/1 Running 0 88s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/gloo ClusterIP 10.100.162.70 <none> 9977/TCP,9976/TCP,9988/TCP,9979/TCP 88s
service/ingress-proxy LoadBalancer 10.107.107.38 192.168.31.11 80:32207/TCP,443:32228/TCP 88s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/discovery 1/1 1 1 88s
deployment.apps/gloo 1/1 1 1 88s
deployment.apps/ingress 1/1 1 1 88s
deployment.apps/ingress-proxy 1/1 1 1 88s
NAME DESIRED CURRENT READY AGE
replicaset.apps/discovery-9694c78f6 1 1 1 88s
replicaset.apps/gloo-7cd566cb69 1 1 1 88s
replicaset.apps/ingress-7fb5c9687d 1 1 1 88s
replicaset.apps/ingress-proxy-5cc555c45b 1 1 1 88s
샘플 petstore 서비스를 배포하고, 인그레스 클래스 어노테이션을 kubernetes.io/ingress.class: gloo로 선언하고 ddiiwoong.com 호스트 이름으로 배포한다.
kubectl apply -f \
https://raw.githubusercontent.com/solo-io/gloo/v1.2.9/example/petstore/petstore.yaml
cat <<EOF | kubectl apply -f -
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: petstore-ingress
annotations:
# note: this annotation is only required if you've set
# REQUIRE_INGRESS_CLASS=true in the environment for
# the ingress deployment
kubernetes.io/ingress.class: gloo
spec:
rules:
- host: ddiiwoong.com
http:
paths:
- path: /.*
pathType: ImplementationSpecific
backend:
service:
name: petstore
port:
number: 8080
EOF
> kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
petstore-ingress <none> ddiiwoong.com 192.168.31.11 80 7m41s
해당 호스트로 정상 라우팅되어 접속되는 것을 확인할 수 있다.
> curl -H "Host: ddiiwoong.com" 192.168.31.11/api/pets
[{"id":1,"name":"Dog","status":"available"},{"id":2,"name":"Cat","status":"pending"}]
GitOps 컨트롤러로 클러스터 관리
gitops 오픈소스인 Flux를 사용해서 여러가지 클러스터 관리를 수행할 수 있다. 위에서 생성한 desired state인 클러스터 컨피그를 github repo에서 Flux 컨트롤러를 통해 클러스터 운영을 수행할 수 있다.
https://anywhere.eks.amazonaws.com/docs/tasks/cluster/cluster-flux/
Worker 노드와 Control Plan, Etcd등의 vSphere에서 관리하는 datastore, 디스크, 메모리, CPU, resourcepool 등을 관리할 수 있다. 단, EKS의 관리형 노드그룹과 유사한 방식으로 노드그룹의 VM의 숫자를 늘리거나 줄일수 있지만 아직까지 신규로 worker 노드그룹을 생성하거나 삭제하는 기능은 제공하지 않는다.
초기 클러스터 컨피그에 아래와 같이 기존 노드그룹 md-0에 신규 VM 1대를 추가해보자. (2대->3대)
clusters/$CLUSTER_NAME/eksa-system/eksa-cluster.yaml
apiVersion: anywhere.eks.amazonaws.com/v1alpha1
kind: Cluster
metadata:
name: homelab
namespace: default
spec:
...
workerNodeGroupConfigurations:
- count: 3
machineGroupRef:
kind: VSphereMachineConfig
name: homelab
name: md-0
초기 환경에서 구성된 gitops repo에 수정된 파일을 커밋한다.
git add clusters/homelab/eksa-system/eksa-cluster.yaml
git commit -m 'Scale from 2 to 3 at WorkerNodeGroup md-0 '
git push origin main
md-0 노드그룹에 VM이 새롭게 추가된 것을 확인할 수 있다.
> kubectl get machine -n eksa-system
NAME CLUSTER NODENAME PROVIDERID PHASE AGE VERSION
homelab-etcd-jrhvt homelab vsphere://421b44b1-6017-8469-734b-01bcf68cb459 Running 75m
homelab-j5mql homelab 192.168.31.186 vsphere://421b4382-0727-3afc-5c47-b73455010d35 Running 75m v1.21.5-eks-1-21-8
homelab-md-0-76478bb486-j68fd homelab 192.168.31.190 vsphere://421bc1ee-eac7-f1db-b351-5fac25b45fc0 Running 11m v1.21.5-eks-1-21-8
homelab-md-0-76478bb486-jszj4 homelab 192.168.31.187 vsphere://421b4dc9-b7c6-f0a2-0b50-e5379748b9a9 Running 75m v1.21.5-eks-1-21-8
homelab-md-0-76478bb486-rpxlm homelab 192.168.31.188 vsphere://421b20a4-9870-cd20-4cff-67bb4a9d8372 Running 75m v1.21.5-eks-1-21-8
homelab-w6bq8 homelab 192.168.31.189 vsphere://421befe9-e26a-3f18-9ccf-3fe32dd57fd2 Running 75m v1.21.5-eks-1-21-8
정리
이번 포스팅에서는 eks-anywhere 오픈소스를 vSphere 홈서버에서 테스트를 진행한 경험을 정리했다.
설치를 진행하면서 에러가 나면 하나하나 공식 문서를 확인하고, 회사 슬랙 찬스도 사용하면서 힘들게 설치를 완료했다. 생각보다 디버깅을 하는데 많은 시간을 허비했는데 실제로 2일 이상 고생을 했다. 대부분의 경우 디버그 레벨의 로그를 보면서 트러블슈팅을 통해 문제 해결이 가능했고 그 과정에서 EKS Anywhere의 내부 구성요소들과 실제 Cluster API 워크플로우를 이해할 수 있었다.
다만 아직까지 문서화나 커뮤니티에 많은 유스케이스가 없다는 점과 Cilium을 메인 CNI로 활용함에도 불구하고 CiliumNetworkPolicy API를 사용하지 못하는 점이나 Cilium 유저 인터페이스인 Hubble UI를 활성화해서 사용할 수가 없는 제약사항등이 있었고, 쿠버네티스 관련해서는 Persistent Volume 관련하여 vSAN을 사용하지 않은 환경에서는 VMDK를 수동으로 생성하고 해당 볼륨을 매핑시켜야 활용이 가능한 제약사항이 존재하는 것이 조금 아쉬운 부분이다.
실제 프로덕션 환경에서 사용할 정도라기 보단 EKS를 사용하는 관점에서 유사한 경험을 바탕으로 개발환경을 가져갈수 있고 tanzu나 다른 cluster-api를 활용한 도구들 보다 좀더 유연하고 오픈소스에 가까운 경험성을 제공한다고 생각한다. 게다가 Flux의 Server-side reconciliation 기반 쿠버네티스 리소스 관리 방식으로 클러스터를 매우 유연하게 관리할 수 있다는 것도 주목해볼만한 내용이라 생각한다. 클러스터 자체도 인프라 리소스라 가정하고 최초에 원하는 형태로 선언하고 구성이후에도 쿠버네티스 CRD 형식으로 노드그룹과 인스턴스 등의 여러 리소스를 GitOps 방식으로 관리하는 방식을 채택하고 있기 때문에 실제 인프라 관리를 하는 운영자를 위한 가장 효과적인 방법을 채택했다고 볼 수 있다.
그리고 표준규격의 Managed 하드웨어를 사용하는 Outpost와 비교하는 자료들이 최근 많이 올라오고 있는데 EKS Anywhere의 가장 큰 장점은 내가 가진 하드웨어를 EKS Distro기반의 오픈소스를 통해 사용할 수 있고 AWS 환경과의 직접적인 통신이 없이도 자체적인 워크로드 운영이 가능한게 가장 큰 장점이라고 생각한다.
현재 재직중인 회사의 제품과 관련해서 로드맵을 자세히 언급하지는 못하지만 엔터프라이즈 vSphere 환경과 동시에 EKS를 사용하는 조직에서는 중요한 하나의 선택지가 될 수 있다는 점에서도 지켜볼만하다고 생각한다.
다음 포스팅에서는 해당 클러스터에 OpenTelemetry collector, Loki, Prometheus 구성을 통한 observability 환경 구성을 진행해볼 예정이다.
해당 포스팅은 현재 재직중인 회사에 관련이 없고, 개인 역량 개발을 위한 자료로 활용할 예정입니다.